Refactoring in cloud migration means making significant architectural and code-level changes to an existing application to optimise it for cloud environments. Instead of simply lifting and shifting a workload, refactoring restructures it to use cloud native services such as managed databases, containers, microservices or serverless computing.
Common migration patterns include rehosting, re-platforming, refactoring, rebuilding or replacing. Refactoring sits in the middle of the modernisation scale, keeping the core application but improving internal structure, removing legacy dependencies, updating frameworks and unlocking new capabilities.
Refactoring requires investment, but the long-term gains are often significant. In doing so, organisations can gain:
Improved scalability and performance
By adapting applications to use cloud native components such as container orchestration, managed databases or asynchronous workloads, organisations can achieve higher performance and better resilience under load.
Reduced long-term costs
Although refactoring may increase migration effort, it often leads to lower operational costs. Cloud-native services offer auto-scaling, pay-per-use pricing and more efficient resource consumption. Over time, this results in better financial performance than traditional lift-and-shift.
Faster delivery and innovation
Refactored applications are usually more modular and easier to update. This supports continuous deployment, quicker releases and faster time to market, which are ideal for product teams and digital delivery.
Lower technical debt and easier maintenance
Refactoring replaces old libraries, removes legacy components and reduces complexity. This improves stability and simplifies systems for engineering teams to maintain and enhance.
Stronger security and compliance
Modern cloud architectures embed identity management, encryption, monitoring and audit controls. This makes it easier to meet regulatory requirements and improve security posture.
Future-readiness and flexibility
Refactored solutions adapt more easily to new technologies, cloud services and business requirements. They are better positioned for AI integration, data platform modernisation and future cloud strategies.
Challenges of refactoring in cloud migration
Refactoring is one of the more advanced cloud migration strategies, which lends itself to complications. Some of the challenges to be aware of include:
Higher upfront effort and cost
Refactoring requires redesigning and rewriting parts of the application. This means more time and investment compared to rehosting or re-platforming.
Complex transformation risk
Innate changes to architecture may introduce new bugs or operational risk. Without careful planning, live services may face disruption during cutover.
Legacy constraints and dependencies
Some applications are tightly coupled or built on outdated frameworks, which makes refactoring more time consuming. Legacy systems may require major rework before they are cloud-ready.
Risk of cloud provider lock-in
Cloud-native services offer significant value, but can complicate multi-cloud strategies. Organisations must balance innovation with portability requirements.
Cloud skill gaps across teams
Refactoring requires cloud architecture expertise, software engineering capability, DevOps skills and updated security practices. Many organisations are still building on skills in these areas.
Delayed return on investment
Refactoring benefits increase over time. Stakeholders may expect instant cost savings, which can create pressure if results take longer to appear.
Best practices for cloud migration refactoring
Refactoring is most successful when approached with structure and clarity. The following best practices can help reduce risk and improve outcomes:
1. Carry out a complete application assessment
Review application dependencies, integrations, data flows, technical debt, scalability and risk. This helps map the complexity of the estate and segment workloads based on refactoring suitability.
2. Prioritise the right applications
Focus refactoring on high-value workloads such as customer facing services, highly scaled systems or applications requiring innovation. Avoid refactoring low-value or soon-to-be-retired solutions.
3. Create a clear business case and measurable KPIs
Define long-term success: improved performance, cost efficiency, error reduction, increased release frequency or reduced maintenance overhead. Tie each refactoring decision to a measurable outcome.
4. Adopt cloud native architecture patterns
Use microservices, event-driven design, serverless functions, containers, managed data services, API gateways and infrastructure as code. CACI’s Cloud Engineering and Implementation Services helps organisations effectively adopt this.
5. Embed security and governance from the beginning
Security must not be retrofitted. Implement identity and access management, encryption, logging, monitoring, network controls and compliance checks early.
6. Invest in skills and organisational readiness
Support DevOps adoption, cloud architecture upskilling and platform engineering capabilities. Consider establishing a cloud centre of excellence.
7. Deliver refactoring in waves
Avoid large, risky transformations. Move applications into the cloud in phases: pilot, assessment, refactor, migrate, validate and optimise. This will reduce risk and increase confidence.
Cloud migration with CACI
Refactoring during cloud migration can unlock scalability, performance, agility and long-term cost savings. However, success depends on having the right expertise, governance, cloud architecture and migration strategy.
If you are planning to refactor applications for cloud or considering a modernisation strategy, get in touch with us to find out how CACI can help you achieve scalable, secure and cost-effective results.
Cloud innovation trends: Why optimisation must come first
Michael Cafferty
In this Article
Cloud innovation trends: Why optimisation must come first
In the race to modernise, many businesses make a critical mistake: innovating before optimising their cloud infrastructure. It’s an easy trap to fall into – new technologies promise speed, agility and competitive advantage. However, without a solid foundation, those promises can quickly unravel.
So, what difference will optimisation make to cloud innovation? How do complex hybrid environments affect optimisation and what are the repercussions of innovating too soon?
Why optimisation should come first
Cloud optimisation isn’t just a technical exercise – it’s a strategic imperative. Before you invest in AI-driven tools, advanced analytics or multi-cloud deployments, you need to ensure your existing environment is efficient, secure and cost-effective. Otherwise, innovation becomes a gamble rather than a growth driver.
How the complexity of hybrid environments affects optimisation
Modern IT landscapes are rarely simple. Most organisations operate in hybrid environments, combining:
Cloud-native workloads
Semi-native applications
Containerised services
Legacy systems migrated via IaaS.
This mix introduces complexity that can quietly erode ROI and performance. Without optimisation, you risk inefficiencies that undermine every future initiative.
Common pitfalls of innovating too soon
When businesses rush to innovate without first optimising, they often encounter:
Duplicated workloads
Hybrid setups frequently lead to duplication of environments or services, especially when containerised and legacy systems overlap with cloud-native tools. This consumes bandwidth and burdens IT and DevOps teams with managing multiple versions of the same workload.
Latency issues
Poor workload distribution across cloud environments increases latency, slowing response times and masking compliance or security issues. For customer-facing applications, this can directly impact user experience and brand reputation.
Security saps
Unoptimised containerised and legacy workloads are vulnerable to governance and compliance risks. Differences in data storage and flow between environments complicate tracking, while unresolved legacy issues can carry over post-migration.
Mounting costs
With up to 30% of cloud spend wasted, inefficiencies inflate monitoring and security costs, draining budgets that could fund innovation.
Why this matters now
Cloud strategies are under pressure to deliver more – faster, cheaper and greener. Without optimisation, businesses risk inefficiency, higher costs and vulnerabilities that stall progress. In an industry where every second counts, building on shaky ground isn’t just risky, it’s expensive.
How to get started
Before chasing the next big trend in cloud innovation, take time to:
Audit your current architecture: Maintain visibility by understand what’s running, where and why.
Identify duplicated workloads and inefficiencies: Determine whether any services or resources are the cause behind draining budgets.
Align resources with business priorities: Ensure any spending on cloud innovation drives value for the business.
Implement governance and security best practices: Establishing best practices early on will ensure that innovation is scaled effectively.
This foundation ensures innovation is sustainable, not just a short-term fix.
The CACI approach: Building a cloud that enables innovation
Ready to build a cloud foundation that enables innovation?
Don’t leave your cloud strategy to chance. Our specialist cloud architects and optimisation experts have helped leading organisations modernise, streamline and unlock innovation without compromise. Contactus today to start your cloud optimisation journey.
Case study
How CACI helped Network Rail develop & manage an open data service
Summary
National Rail Open Data (NROD) provides the public with access to a large number of operational data feeds to encourage both greater interest in rail and the development of innovative products that are of use to passengers and the rail industry. CACI processes and manages the NROD platform with the aim of providing continual and easy access to users.
Company size
42,000
Industry
Transport
Products used
Challenge
Network Rail provides a variety of data in different formats from XML, JSON and rail proprietary data structures. These are received with varying levels of frequency from static data to real-time data updated at up to 100 messages per second during peak hours. Our instruction from Network Rail was for the data to be made available with no obfuscation or filtering applied to make it as accessible and easy to use as possible.
Varied data formats
Inconsistent frequency
Need accessibility
Solution
To achieve this, we offered options for users by providing some conversions (such as to JSON) and enriching data with metadata. We also used AWS infrastructure and highly available components like AWS ECS (Elastic Compute Service) and S3 (Simple Storage Service) to improve access and availability.
Users were provided a portal for account management, allowing them to change details such as their username and password and access links to documentation and endpoint information for the data to aid their use and interpretation. A separate portal manages access for industry clients invited by Network Rail, allowing them to connect to a more stable platform for use in industry applications.
Results
NROD is now used by an engaged, passionate community of over 600 registered users who apply the data in a variety of ways. Since the data was first made available, a range of websites and apps have been created, including Open Train Times, which provides real-time arrival and departure information for each train company and helps passengers plan their journeys, along with Recent Train Times, demonstrating individual trains’ performance and helping users assess the punctuality of different train services to plan their journeys accordingly.
CACI has been collaborating with industry clients and representatives of the broader public client community in a working group to give updates and receive feedback on how best the community can be served. We also discuss enhancements and how to collaborate to address users’ needs at quarterly meetings.
A Grafana dashboard has been developed to keep users informed on the system’s status, including message rates, message latency of the main feeds and an update field showing system downtime updates.
To ensure NROD is accessible to as many audiences as possible, we have worked with Network Rail to provide the same data within the Rail Data Marketplace (RDM), adding to the 100+ other rail data products now available on this platform.
Testimonial
Network Rail’s Open Data is essential to supporting the development of new applications and services in rail. CACI’s expertise in large scale infrastructure, complex datasets and real-time feeds is key to this, ensuring that the user community of developers and rail professionals always has access to the data and that it is easy to use. By directly engaging with users, CACI continually improves the service, further enabling innovation in rail.
Network Automation and NetDevOps are hot topics in the network engineering world right now, but as with many new concepts, it can be confusing to decipher the meaning from the noise in the quest to achieving optimal efficiency and agility of network operations.
A useful starting point would be to first define what network automation is not:
Network automation is not just automated configuration generation or inventory gathering
It is not just using the same network management system (NMS) as today but faster
It is not just performing patching and OS upgrades faster, or network engineers suddenly becoming software developers
Network automation is not going to work in isolation of changing lifecycle and deployment processes, nor is it a magic toolbox of all-encompassing applications, frameworks and code.
At CACI, we view network automation as both a technology and a business transformation. It is as much a cultural shift from legacy deployment and operations processes as it is a set of tools and technology to implement speed, agility and consistency in your network operations. Infrastructure is changing fast, and with Gartner reporting 80% of enterprises will close their traditional data centres by 2025, the only constant in networking is that change will persist at faster clip.
So, how does Network Automation work? What differentiates network automation from NetDevOps? What difference can it make to modern IT operations, and which best practices, technologies and tools should you be aware of to successfully begin your network automation journey?
How does Network Automation work?
Network Automation implements learnings from DevOps developments within the software development world into low-level network infrastructure, using software tools to automate network provisioning and operations. This includes techniques such as:
Anomaly detection
Pre/post-change validation
Topology mapping
Fault remediation
Compliance checks
Templated configuration
Firmware upgrades
Software qualification
Inventory reporting.
In understanding how these differ from traditional network engineering approaches, it is important to consider the drivers for network automation in the post-cloud era – specifically virtualisation, containerisation, public cloud and DevOps. These technologies and approaches are more highly scaled and ephemeral than traditional IT Infrastructure, and are not compatible with legacy network engineering practices like:
Using traditional methodology to manage infrastructure as “pets” rather than “cattle”
Box-by-box manual login, typing CLI commands, copy-pasting into an SSH session, etc.
“Snowflake networks” which don’t follow consistent design patterns
Network automation aims to change all this, but to do so, must overcome some obstacles:
Cross-domain skills are required in both networking and coding
Some network vendors do not supply good API or streaming telemetry support
Screen scraping CLIs can be unreliable as CLI output differs even between products of the same device family.
Cultural resistance to changes in both tooling and practice
Lack of buy-in or sponsorship from the executive level can compound these behaviours.
What differentiates network automation from NetDevOps?
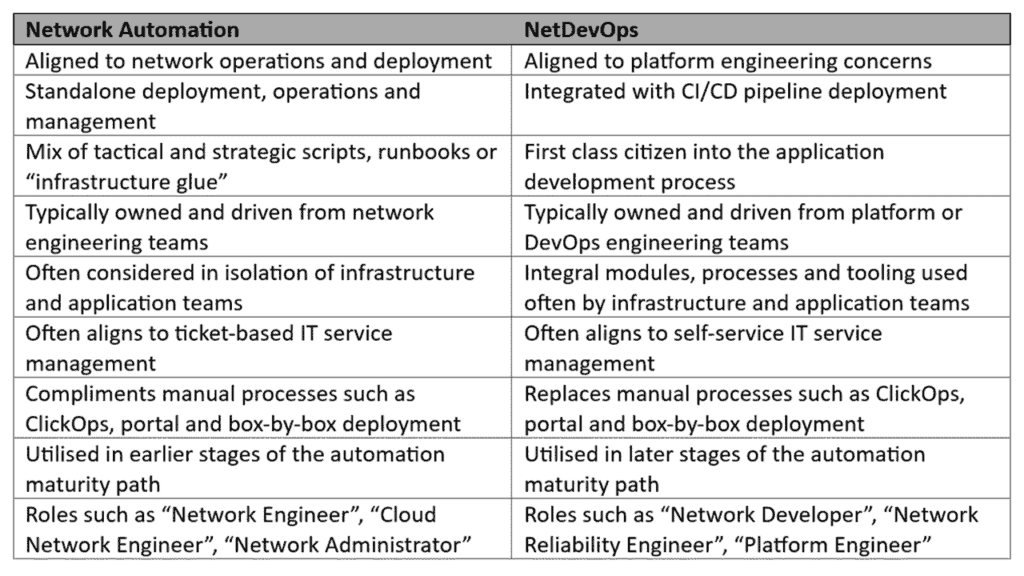
You may also have heard of “NetDevOps” and be wondering how – or if – this differs from network automation. Within CACI, we see the following key differences:
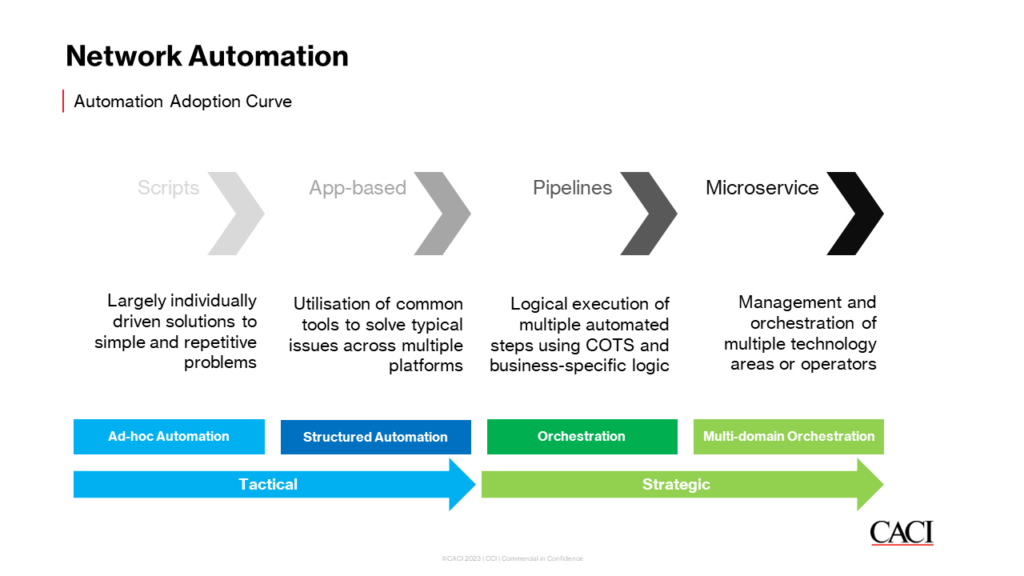
We often see our clients use a blend of both in practice as they go through the automation adoption curve into the automation maturity path, from ad-hoc automation, through structured automation, into orchestration and beyond:
What difference can network automation make to modern IT operations?
Network automation aims to deliver a myriad of business efficiencies to IT operations, helping reduce labour and hours worked, time to deploy and operational costs while improving performance and agility. This has proven to be transformational across our wide and varied client base, with improvements demonstrated in the following ways:
Increased efficiency
Much of networking is repetition in differing flavours – reusing the same routing protocol, switching architecture, edge topology or campus deployment. A network engineer is often repeating a task they’ve done several times before, with only slight functional variations. Network automation saves time and costs by making processes more flexible and agile, and force-multiplying the efforts of a network engineering task into multiple concurrent outputs.
Reduced errors
Networking can be monotonous, and monotony combined with legacy deployment methodology can cause repetition of the same error. Network automation reduces these errors – particularly in repetitive tasks – to lower the chances of reoccurrence. When combined with baked-in, systems-led consistency checking, many common – but easily-avoidable – errors can be mitigated.
Greater standardisation
Networks are perhaps uniquely both the most and least standardised element of the IT stack. While it is easy to have a clean “whiteboard architecture” for higher-level concerns such as application development, the network must often deal with the physical constraints of the real world, which, if you’ve ever tried to travel to a destination you’ve not been to before, can be messy, confusing and non-sensical. Network automation ensures the starting point for a network deployment is consistent and encourages system-level thinking across an IT network estate over project deployment-led unique “snowflake” topologies.
Improved security
Increased security often comes as a by-product of the standardisation and increased efficiency that network automation brings. Most security exploits are exploits of inconsistency, lack of adherence to best practice or related – which ultimately pivot around “holes” left in a network (often accidentally) due to rushing or not seeing a potential backdoor, open port, misconfiguration or enablement of an insecure protocol. When combined with modern observability approaches like streaming telemetry and AIOps, network automation can help enforce high levels of security practice and hardening across an IT estate.
Cost savings
Given its position as the base of the tech stack, the network is often a costly proposition – with vertically-integrated network vendors, costly telco circuit connectivity, expensive physical world hosting and colocation costs, and so on – the network is often a “get it right first time” endeavour which can be cost-prohibitive to change once live and in service. Network automation encourages cost savings through the creation of right-the-first-time and flexible network topologies and in performing design validation which can minimise the amount of equipment, licensing, ports and feature sets required to run a desired network state.
Improved scalability
As both consumer and enterprise expectations of scale are set by the leading web scalers of the world, the enterprise increasingly expects the flexibility to scale both higher and lower levels of the IT stack to larger and more seamless sizes, topologies and use cases. Network automation aids in achieving this through the enforcement of consistency, modularisation, standardisation and repeatability for network operations.
Faster service delivery
IT service delivery is increasingly moving away from being ticket-led to self-service, with the lower-level infrastructure elements expected to be delivered much faster than the traditional six-to-eight-week lag times of old. As telco infrastructure moves through a similar self-service revolution, so too does the enterprise network require the ability for self-service, catalogue-driven turn-up and modularised deployment. Network automation enables this by optimising network performance to the required parameters of newer services and applications in the modern enterprise.
What are the best practices for network automation?
Network automation is as much a cultural transformation as it is a technology transformation. Much as DevOps disrupted traditional ITIL and waterfall approaches, NetDevOps similarly disrupts current network engineering practices. We find the following best practices to be beneficial when moving towards network automation:
Choose one thing initially to automate
Pivot around either your biggest pain point or most repetitive task
Don’t try to take on too much at once. Network automation is about lots of small, repeated, well-implemented gains which instil confidence in the wider business
People love automation, they don’t want to be automated. The biggest barrier to adopting automation will be keeping colleagues and stakeholders on-side with your efforts by showing the reward of that they provide to them and to the wider business.
Choose tooling carefully
Stay away from the “latest shiny” and pick open, well-used tools with large libraries of pre-canned vendor, protocol and topology integrations, and human-readable configuration and deployment languages
Maintain your specific business context during tool selection
Think ahead for talent acquisition and retention – writing custom Golang provisioning application might be handy today, but you could struggle to get others involved if the author decides to leave the business.
Optimise for code reusability
Build and use version control systems such as Git, GitHub and Azure DevOps from day one and encourage or even mandate their use
Advocate for the sharing of functions, modules, routines and snippets written within code, runbooks, IaC and state files within scrapbooks and sandpits. The flywheel of productivity increases exponentially within NetDevOps as increasingly more “we’ve done that before” coding and practices accelerate the development of newer, more complex routines, IaC runbooks and functions
Code should be written with reuse and future considerations in mind. While it may be tempting to “save ten minutes” so as to not functionise, modularise or structure code, this will catch up with you in the future.
Use templating for configuration generation
Templating programmatically generates the vendor-specific syntax for a network device based on a disaggregated, vendor-neutral input format (such as Jinja2, Mako or Markdown) which is later combined with data (such as specific VLANs, IP Addresses or FQDNs) to generate the vendor-specific syntax (such as Cisco IOS, Arista EOS or Juniper Junos) for the network device
The act of creating the templates has an added by-product of forcing you to perform design validation. If your design document doesn’t have a section covering something you need template syntax for, it could well be due for an up-issue
Templates become a common language for network intent that are readable by all network engineers regardless of their individual network vendor and technology background, aiding in time to onboard new staff and ensuring shared understanding of business context around the IT network.
Which tools, frameworks and languages enable network automation?
There are a myriad of network automation tools, frameworks, languages and technologies available today. DeThere are a myriad of network automation tools, frameworks, languages and technologies available today. Deciphering these can be confusing, but a good starting point is categorising the distinct types of network automation tooling available:
Network Configuration and Change Management (NCCM)
Enable patching, compliance and deployment (rollout)
Often align to network management systems (NMS) or BSS/OSS (Telco space)
Abstract network device box-by-box logic into estate-wide, policy-driven control
Often align to industry frameworks and controls (SOC2, HIPAA, CIS, PCI/DSS)
Intent-Based Networking Systems (IBNS)
Translate business intent through to underlying network configuration and policy
Are starting to become the “new NMS”
It would be exhaustive to list all possible tools, frameworks and languages available today, but these are some of our most seen within our client base today. Our current favourites can be seen in What are the most useful NetDevOps Tools in 2023?:
Tools
Terraform – An open-source automation and orchestration tool capable of building cloud, network and IT infrastructure based on input Infrastructure as Code (IaC) code via HCL (HashiCorp Configuration Language) that defines all attributes of the device and configuration blueprint required. Terraform is highly flexible and has a vast array of pre-built modules and providers for most network engineering concerns via the Terraform Registry.
Ansible – An open-source automation and orchestration tool typically used to configure within the device rather than provision the underlying Baremetal or cloud infrastructure the cloud, network or IT device sits atop, which is based on input IaC code via YAML that defines the attributes and device configuration required. Ansible is versatile and has a large cache of pre-built runbooks and integrations for network engineering concerns via Ansible Galaxy.
NetBox – The ubiquitous, open-source IP Address Management (IPAM) and Data Centre Infrastructure Management (DCIM) tool, which acts as the Network Source of Truth (NSoT) to hold a more detailed view of network devices, topology and state than could be achieved via alternative approaches such as spreadsheet or CMDB. NetBox is highly customisable, with a rich plugin ecosystem and customisable data models via YANG to adapt around business-specific topology data models.
Git – The de facto version control system, which is the underlying application that powers GitHub and GitLab and supplies a mechanism to store IaC, configuration and code artefacts in a distributed, consistent and version-controlled manner. Git is pivotal in enabling the controlled collaboration on network automation activities across a distributed workforce while maintaining the compliance and controls required within the enterprise environment.
Nornir – An automation framework written in Python to automate a network, streamlining and simplifying automation for network engineers already versed in Python.
Frameworks
Robot framework: A generic test automation framework allowing network automation code and IaC runbooks to run through acceptance testing and test-driven development (TDD) via a keyword-driven testing framework with a tabular format for test result representation. It is often used in conjunction with tools such as pyATS, Genie, Cisco NSO and Juniper NITA.
PEP guidelines: Short for Python Enhancement Proposals (PEP), these are to Python what RFCs are to network engineering, and provide prescriptive advice on setting out, using, structuring and interacting with Python scripts. The most commonly known of these is the PEP8 – Style Guide for Python.
Cisco NADM: The Cisco Network Automation Delivery Model (NADM) is a guide on how to build an organisation within a business around an automation practice, addressing both the human aspect as well as some of the tooling, daily practices, procedures, operations and capabilities that a network automation practice would need to take traction in an IT enterprise landscape.
Languages
Python: The de facto network automation coding language, utilised as the underlying programming language in tools from NetBox, Nornir, Batfish, SuzieQ, Netmiko, Scrapli, Aerleon, NAPALM and more, popularised by its extensive network engineering-focused library within PyPi. Python is the Swiss army knife of NetDevOps, able to turn its hand to ad-hoc scripting tasks through to full-blown web application development using Flask or API gateway hosting using FastAPI.
Golang: An upcoming programming language, which benefits over Python in terms of speed via a compiler-based approach, parallel-execution, built-in testing and concurrency capabilities when compared to Python. On the downside, it has a significantly steeper learning curve than Python for new entrants into the realm of development and has far fewer network engineering library components available to use.
What does the future of network automation look like?
Machine learning (ML) in conjunction with AI are becoming increasingly embedded into network operations and the demand for network automation and NetDevOps professionals is undoubtedly on the rise. This is a trend that we at CACI expect to continue as budgetary pressures from the macroeconomic climate accelerate and trends like artificial intelligence (AI) begin to challenge the status quo and push businesses to deliver seamless, scalable network fabrics with more expectation of self-service and less tolerance of outage, delay or error. With this, automation will continue to shift from reactive scripts to intelligent networking capabilities.
We see more of our clients moving up through the automation maturity path towards frictionless and autonomous network estates and expect this to accelerate through the coming years with ancillary trends such as NaaS (Network as a Service), SDN (Software Defined Networking) and NetDevOps set to continue and embed the NetEng Team firmly into the forthcoming platform engineering teams of tomorrow.
How can CACI help you on your network automation journey?
With our proven track record, CACI is adept at a plethora of IT, networking and cloud technologies. Our trained cohort of high calibre network automation engineers and consultants are ready and willing to share their industry knowledge to benefit your unique network automation and NetDevOps requirements. We are a trusted advisor that ensures every team member is equipped with the necessary network engineering knowledge from vendors such as Cisco, Arista and Juniper, along with NetDevOps knowledge in aspects such as Python for application Development, NetBox for IPAM and NSoT, Git for version control, YAML for CI/CD pipeline deployment and more.
Our in-house experts have architected, designed, built and automated some of the UK’s largest enterprise, service provider and data centre networks, with our deep heritage in network engineering spanning over 20 years across a variety of ISP, enterprise, cloud and telco environments for industries ranging from government and utilities to finance and media.
Get in touch with us today to discuss more about your network automation and NetDevOps requirements to optimise your business IT network for today and beyond.
Three ways digital twins can transform small airports
Harsh Tandon
In this Article
When people talk about digital twins, they often picture a virtual representation of a physical thing such as an airplane, allowing simulation of changes to design and measuring against different variables to see the impact of those changes. This leads to innovative designs, because the risk of R&D is greatly reduced when able to test hypotheses in the safe space of the virtual world. The beneficial impact of digital twins doesn’t end with physical assets, however. The same principles can be applied to whole systems, be it the communications system used on board that plane or the whole ecosystem required to get the plane safely off the ground, with the right passengers, the right baggage, the right fuel and the right flight plan. Whether a sprawling international hub with thousands of flights per day or a smaller airport like the one we visited in Staverton, digital twins can enable rapid optimisation and growth and great reductions in waste and errors. So, what are three pivotal ways in which digital twins can make a difference? A Digital Twin — a virtual replica of a physical asset or a system capable of revolutionising how regional airports manage their resources, optimise operations and plan for the future. Gloucestershire Airport, servicing private aircraft, helicopters and even emergency landings, is the perfect example of where this innovation could have a real, immediate impact. 1. Fuel Management: beyond just “how much?” Fuel is the lifeblood of an airport’s operations, and in smaller airports, every litre counts. By deploying sensors on refuelling tanks and storage facilities, airports can continuously monitor both the quantity and quality of fuel in real time. Moisture ratings, contaminant detection and temperature controls would ensure fuel meets strict aviation standards, minimising the risk of supply issues or quality failures. Using historical demand patterns combined with predictive analytics, a digital twin could forecast fuel usage trends, allowing smarter resupply scheduling. Not only would this optimise operational costs, but it could also reduce the carbon footprint associated with frequent, unnecessary fuel deliveries. 2. Full operational visibility:from touchdown to take-off Imagine a live, data-driven view of the entire airport, from a helicopter’s landing and its passengers’ disembarkation to baggage handling efficiency. A digital twin could integrate sensor data, RFID tracking, business systems and operational logs to create a single pane of glass for airport managers. Delays in passenger flow? The system would spot them instantly. Baggage bottlenecks? Highlighted before they become a passenger satisfaction issue. Even emergency landings could be better coordinated with real-time scenario simulations. 3. Learning from the past and testing the future One of the most powerful advantages of a digital twin is its ability to simulate “what if” scenarios without touching the real-world setup. Historical analysis: Why did baggage handling slow down during the last peak season? Where could staffing have been more efficient? Virtual experimentation: What happens if a new refuelling procedure is trialled? What’s the impact of changing the location of helicopter landing pads? By creating a safe environment to design and test improvements virtually, smaller airports could avoid costly, disruptive errors and implement proven optimisations with confidence. How CACI can help you reap the benefits of digital twins Digital twins aren’t reserved for the world’s largest airports or organisations. They offer just as much– if not more– value to smaller, agile organisations where every efficiency gain translates to a significant operational advantage. The future of aviation infrastructure isn’t just about scaling up. It’s about scaling smart, starting with embracing the power of a digital twin. Discover more about Mood’s cutting-edge advancements in digital twins with our latest video, created in collaboration with CyNam. We delve into real-world applications of digital twins, offering insights into how these virtual replicas can address challenges and drive innovation.
Case study
Activating data for a flagship customer experience project for the RAC
Summary
The RAC provides complete peace of mind to more than 12.7 million UK personal and business members, whatever their driving needs. They’re famous for breakdown assistance, but they also provide motor insurance and a range of other services, including buying a new or used car, vehicle inspections and checks, legal services and traffic and travel information.
Company size
1,000 – 5,000
Industry
Transportation & Logistics
Services used
Products used
Challenge
The RAC had outgrown its relatively basic campaign tool. They needed something more flexible and efficient to transform the existing manual and time-intensive process for campaign delivery. Their on-premise SQL solution was hosted by a third-party agency. Poor access to data constrained the RAC marketing team, which needed to be more self-sufficient in campaign operations.
The RAC’s Data and CRM Strategy Leader, Ian Ruffle, says: “Because the legacy technology wasn’t efficient, it took over 48 hours to refresh the data. If it fell over, as it often did, because we were at the limits of the solution’s capability, it could take up to ten days from a customer being acquired to reflect that in the marketing solution. This was becoming a real problem.”
Solution
The RAC and CACI worked together to implement a suite of tools to transform the RAC’s marketing capabilities and to create the efficiencies and flexibility they needed. The first step was to build a single customer view (SCV) database using Snowflake. The pay-by-consumption processing function made it scalable and cost effective as well as future-proof. This gave the RAC direct access and control of their own data, which was a key requirement. Within Snowflake, CACI built a secure, accurate and compliant dataset, in line with GDPR requirements.
The database is hosted in the MS Azure cloud, and is refreshed and managed using Azure Functions, event triggers and DBT models. CACI’s resolution identity product, ResolvID, also plays a part in the solution. It’s hosted in Amazon Web Services (AWS) and consumed in real-time as event-triggered files are added into the database. This gives the RAC a complete view of each customer across multiple datasets and sources, allowing them to engage their customers in a more holistic way.
CACI implemented Adobe Campaign, Target and Analytics. For the campaign implementation, the team created 42 different tables and two different data structures – one for the B2C side of RAC’s business and one for the B2B side. Then, the RAC and CACI worked together to migrate all their existing campaigns from their legacy solution into the new Adobe Campaign instance, automating everywhere that was possible.
Adobe Triggers mean that web-based events from the customer can feed through into Adobe Campaign in real time. The RAC are using this for their enhanced abandoned baskets campaign. Communication can be triggered instantly, catching customers at a key point in the purchase lifecycle.
With Adobe Target, customer journeys can be personalised throughout the RAC’s website. Now, when a customer lands on the home page, they see personalised content based on interaction they’ve had with the brand before and products that they have or have not purchased.
Results
CACI’s team worked closely with the RAC design team to create them an on-brand template within the CACI Email Studio application. This reduced their previous dependency on third party creative agencies. Now, the RAC team is empowered to control and to create their own emails, without needing an HTML skillset. Email Studio delivers confidence in the usability and the rendering of emails when they land in the customer’s inbox, making sure it’s a positive experience throughout.
Ian Ruffle quantifies the value of the transformation: “Our marketing activation project has delivered a seven-fold improvement in data latency. We’re getting a reliable daily build of the core tables, plus many tables maintained in real time or via hourly batch processes, to meet the various trigger needs of the business.
“75% of the campaigns in the new solution are fully automated. We’re in the process of embedding this for newer campaigns. This gives our teams a huge amount more time to think about how to optimise the campaign and get the best ROI. At the roadside, when customers aren’t sure where their patrol was, they phone us. We’ve seen a 6% reduction in these calls, which is huge for us. It’s a massive cost saving and a much better customer experience, to be kept fully informed”
Testimonial
Our vision is that when a customer comes to our website they are recognised and have a personalised, meaningful experience. We respond to abandoned baskets in a timely and relevant way. We present offers dynamically and consistently across all channels. When a customer breaks down at the roadside, we can access the right data fast to send communications and updates. We’re well on the way to achieving this vision and we’re excited about the future potential of our new Martech stack through our partnership with CACI.
Using FUSION to power and project manage major upgrade work
Summary
CACI’s FUSION methodology is designed to deliver projects on time and in budget. Following three key phases – shape, create and utilise – FUSION sets out the vision, goals and timelines of all customer delivery and internal development work. This case study looks at how CACI’s Cygnum workforce management and scheduling software went through a major enhancement project to deliver a new release, Cygnum 2020, overseen internally using FUSION. This included improving the software, ensuring future compliance for users and the release of a mobile app to support enhanced usability of Cygnum.
Industry
Technology
Products used
Solution
As with all projects, it is important to fully understand, as a team, why we are creating a project and what it needs to achieve. “We had been working alongside our customers for a number of years to deliver software development projects which were often bespoke,” explains Luke Brown, project manager for Cygnum 2020. “Components of these projects were actually beneficial to all our customers, so a new release made it possible to amalgamate these as standard for everyone. Research and development we had been working on internally was also included, as was any ongoing compliance updates, be they for data and security regulations or third-party compatibility.”
This would bring benefits to everyone by delivering enhanced functionality and the creation of a common platform for future development. A release like this also makes customer support of Cygnum more straightforward by having commonality in use of the system and satisfying compliance concerns for all.
“Once we understood what the project needed to achieve, it enabled us to focus on the mobilisation and discovery stages of FUSION,” says Luke. “A good example of this is the mobile app that we wanted to create for Cygnum. Extending the usability of Cygnum made a great deal of sense and was something that customers were keen to see. We identified the need to cover mobile forms via the app, essentially making the capturing of data for field-based workers available in real-time, so that they could log data on the move. This would then bring more benefits to more of our customers.”
“Once we had established an agile approach to the FUSION methodology that was to drive the Cygnum 2020 project, we went into a phase of building and testing, building and testing,” says Luke. “This helped the Cygnum team to ensure that everything was coming together as planned.”
Since Cygnum was undergoing a number of functionality enhancements, it was important that the team then started working on the Cygnum user guides to incorporate the changes that Cygnum 2020 would introduce. This started with a number of internal sessions to upskill the team to help them prepare for the launch of Cygnum 2020.
“Education of staff internally was hugely important,” stresses Luke. “Not only did it help team members to prepare on an individual basis, we were able to listen to their feedback and establish areas where we could perhaps be a little clearer in our use of language and terminology.“
“At the same time this supported the verify stage of the project. We were using QMETRY, a Jira add-on, which was supporting the constant process of building and testing that underpinned the create stage of Cygnum 2020. This helped us with the all-important stress testing, too, which consisted of two rounds of regression testing.”
Results
Once the shape and create stages of any FUSION project are completed, it is time to focus on the utilise aspect of the project. “A major aspect of the utilise stage for Cygnum 2020 was awareness,” says Luke. “We had to make everyone in our wider team aware of Cygnum 2020 and what it meant, before engaging with our marketing colleagues to establish materials and campaigns to help us with customer awareness.
“This included updating user guides, a webinar which was recorded by Cygnum solutions architect, Kristen Butler, supporting marketing materials including a teaser campaign and glossy, detailed release notes that our customers could use to generate interest in the upgrade work amongst their teams when they came to implementing Cygnum 2020. This relied heavily upon the work completed in the create stage of the project, since the team was able to draw upon its own internal education to help inform the awareness element for clients.”
This then turned into the transition phase of the project, with a go-live date for release established and a number of customer upgrade orders to fulfil immediately! The transition phase is ongoing, as is the final element of the project, evolve.
“The evolve phase has already started,” explains Luke. “We are already getting feedback from customers and our own internal processes which are informing the future roadmap for Cygnum; we’re not resting on our laurels and patting ourselves on the back for a job well done, we’re looking for ways to continue to evolve Cygnum and make it even better for the next release.”
Cygnum 2020 went live in May 2020. Using the proven project delivery methodology of FUSION, the team was able to operate the process smoothly, on time and in budget. FUSION is the delivery methodology that CACI uses for all of its projects, both internally and customer facing.
How Transport for Greater Manchester increased value from data to understand the people behind travel patterns
Summary
A combination of Transport for Greater Manchester and CACI’s data created insight on customer profiles.
Company size
1,000
Industry
Transport & logistics
Products used
Challenge
Increase the proportion of journeys made by active travel and public transport
Understand variations in the customer profile across different modes of travel, and specific Bus, Metrolink, and cycle routes
Understand barriers to take-up for different user groups (e.g. geographic location, affordability)
Identify appropriate ways to engage with existing customers and target new users
Solution
To overcome these challenges, Transport for Greater Manchester partnered with CACI on the following solutions:
Acorn Postcode, Workforce Acorn, Paycheck and Retail Footprint to enhance its own datasets, including survey data (at the sampling, weighting and analysis stages)
Use with GIS systems to identify spatial patterns and trends
Postcode-level analysis provides a granular understanding that allows for targeted intervention
Results
“CACI’s Acorn, Acorn knowledge base and supporting products (Paycheck, Retail Footprint), used in combination with our own datasets, increase the value we can get from our data and help us to understand in more depth the people behind the travel patterns.”
Rosalind O’Driscoll, Head of Policy Insight and Public Affairs – Transport for Greater Manchester
How CACI helped optimise utilisation of storage capacity across the MoD estate
Summary
The MoD is the UK’s second largest landowner, in possession of 1.1 million acres across the UK (2% of the country’s landmass). Land Usage and Management is crucial to the MoD’s operation and CELLA is paramount in carrying out these critical activities.
In 2020, the Warehousing and Distribution Optimisation (WDO) began a programme to better understand and manage the estate. The WDO needed a central repository that would supply a consolidated view of the wider MoD landscape to bolster planning and decision-making. The solution needed to offer evidence and operational data for the MoD’s ability to function, with a high standard of consistency, accuracy and analytical reporting. This was crucial to the WDO’s objective of increasing efficiency and using reliable evidence to manage efforts, storage capabilities and limitations.
Company size
10,000+
Industry
Defence, National Security, Transportation & Logistics
Services used
Products used
Challenge
The MoD struggled to easily understand the space it maintains and the attributes of its various storage locations. This restricted their planning and decision-making for military operations or civil requirements, particularly storing PPE reserves during the COVID-19 pandemic. Warehousing and other storage facilities were managed on an individual basis without a centralised database or management system, and data storage was often highly siloed.
The WDO decided upon a bespoke solution delivery approach, as there was no readily available commercial off-the-shelf tool that met their complex requirements. The system needed to prompt users (via email) to provide updates, with the frequency of updates having to be configurable based on need (e.g. data for short-term storage facilities should be updated more often than longer-term facilities.)
The data held on the solution needed to be comprehensive, including everything from basic facility type to state of repair and security factors.
Understanding the space available and its attributes
Restrictions on planning and decision-making
Solution
CACI worked with the WDO to optimise and classify their raw data and understand usage and users’ needs. Using Mood’s no-code software, CACI rapidly deployed an integrated solution that put relevant information at the fingertips of decision-makers.
A one-click/two-click navigation created an optimal user experience and encouraged the MoD’s goal of promoting self-sufficiency. Standardised terms and references enabled users to search the entire system, additional permissions-based access could be granted for those users who require it and automated email reminders prompted efficient action.
The Mood platform CACI delivered allows the input data to be filtered and combined in multiple ways to supply answers to operational and planning challenges, such as readiness for military or civilian emergency operations. Functional aspects such as the frequency of automated prompts is configurable to meet local conditions. Data can be exported for secondary reporting (e.g. using Power BI tools).
The frequency of email reminders can be configured on a site-by-site basis to ensure data is updated for sites where storage requirements change regularly while keeping effort low for sites used for long-term storage.
Results
Over 300 buildings are now listed within this tool and WDO users are working towards achieving comprehensive estate coverage. The WDO’s understanding of their operational assets and storage buildings has improved, helping them decide whether particular locations or sites are right for particular actions to optimise their estate. Since delivering the first phase of this programme, we have extended the CELLA capability by adding:
Self-sufficiency: As the solution was being handed over to a central support desk, we ensured that wherever possible, users could maintain the solution themselves and not rely on CACI.
User-specific information: Users’ home screens were updated to showcase information immediately, allowing them to focus on what needed to be done.
Streamlined administration: Users can now access all necessary information about storage sites in one place without having to telephone individual sites and speak to multiple people. Stored items can be located and, just as importantly, storage opportunities can be identified quickly.
The CELLA Data Management Tool (CDMT) team are now working their way around the country to load further sites and hardstandings into the tool. This will give the MoD greater insight into their estate of buildings that is expanding in the face of global instability.
Since transferring to Joint Support in April of this year, the CELLA team have secured multiple storage successes, which will already see savings to the MOD of several million pounds over the next few years. As CELLA continues to mature and understanding of its potential grows, these figures will undoubtedly continue to rise.