When people talk about digital twins, they often picture a virtual representation of a physical thing such as an airplane, allowing simulation of changes to design and measuring against different variables to see the impact of those changes. This leads to innovative designs, because the risk of R&D is greatly reduced when able to test hypotheses in the safe space of the virtual world.
The beneficial impact of digital twins doesn’t endwith physical assets, however.The same principles can be applied to whole systems, be it the communications system used on board that plane or the whole ecosystem required to get the plane safely off the ground, with the right passengers, the right baggage, the right fuel and the right flight plan.
Whether a sprawling international hub with thousands of flights per day or a smaller airport like the one we visited in Staverton, digital twins can enable rapid optimisation and growth and great reductions in waste and errors. So, what are three pivotal ways in which digital twins can make a difference?
A Digital Twin — a virtual replica of a physical asset or a system capable of revolutionising how regional airports manage their resources, optimise operations and plan for the future. Gloucestershire Airport, servicing private aircraft, helicopters and even emergency landings, is the perfect example of where this innovation could have a real, immediate impact.
1. Fuel Management: beyond just “how much?”
Fuel is the lifeblood of an airport’s operations, and in smaller airports, every litre counts. By deploying sensors on refuelling tanks and storage facilities, airports can continuously monitor both the quantity and quality of fuel in real time. Moisture ratings, contaminant detection and temperature controls would ensure fuel meets strict aviation standards, minimising the risk of supply issues or quality failures.
Using historical demand patterns combined with predictive analytics, adigital twin could forecast fuel usage trends, allowing smarter resupply scheduling. Not only would this optimise operational costs, but it could also reduce the carbon footprint associated with frequent, unnecessary fuel deliveries.
2. Full operational visibility:from touchdown to take-off
Imagine a live, data-driven view of the entire airport, from a helicopter’s landing and its passengers’ disembarkation to baggage handling efficiency. A digital twin could integrate sensor data, RFID tracking, business systems and operational logs to create a single pane of glass for airport managers.
Delays in passenger flow? The system would spot them instantly. Baggage bottlenecks? Highlighted before they become a passenger satisfaction issue. Even emergency landings could be better coordinated with real-time scenario simulations.
3. Learning from the past and testing the future
One of the most powerful advantages of a digital twin is its ability to simulate “what if” scenarios without touching the real-world setup.
Historical analysis: Why did baggage handling slow down during the last peak season? Where could staffing have been more efficient?
Virtual experimentation: What happens if a new refuelling procedure is trialled? What’s the impact of changing the location of helicopter landing pads?
By creating a safe environment to design and test improvements virtually, smaller airports could avoid costly, disruptive errors and implement proven optimisations with confidence.
How CACI can help you reap the benefits of digital twins
Digital twins aren’t reserved for the world’s largest airports or organisations. They offer just as much— if not more— value to smaller, agile organisations where every efficiency gain translates to a significant operational advantage.
The future of aviation infrastructure isn’t just about scaling up. It’s about scaling smart,starting with embracing the power of a digital twin.
Discover more about Mood’s cutting-edge advancements in digital twins with our latest video, created in collaboration with CyNam. We delve into real-world applications of digital twins, offering insights into how these virtual replicas can address challenges and drive innovation.
In today’s rapidly evolving business landscape, organisations are seeking innovative ways to enhance efficiency, streamline operations, and drive strategic growth. One of the most transformative concepts to emerge in recent years is the Digital Twin of an Organisation (DTO). This powerful paradigm allows businesses to create a virtual replica of their entire enterprise, enabling real-time analysis, simulation, and optimisation. Among the wide range of tools available, Mood stands out as the unparalleled enabler for creating a comprehensive Digital Twin, offering unmatched capabilities.
What is a DTO?
A DTO is a dynamic, virtual representation of the business, encompassing its processes, systems, capabilities, assets, and data. This digital counterpart takes real-time informationallowing businesses to monitor performance, predict outcomes, and make informed decisions. By leveraging DTO organisations can visualise their entire operation, identify inefficiencies, test scenarios, and implement changes with confidence, all without disrupting actual operations.
The Mood advantage: A unique proposition
Mood offers a unique and comprehensive suite of capabilities for creating and managing a DTO. which makes it the game-changer required:
Holistic Integration:with a whole-systems approach, Mood sits at the centre of your eco-system, mapping a wide range of enterprise systems and data sources, ensuring that your DTO is a true reflection of your organisation, enabling evidence–based decision making. From ERP and CRM systems to IoT devices and data warehouses, Mood consolidates information from disparate sources into a unified, coherent model.
Dynamic Visualisation: With Mood, you can visualise complex processes and structures in an intuitive, user-friendly interface. This dynamic visualisation capability allows stakeholders to easily comprehend intricate relationships and dependencies within the organisation, facilitating data-driven decision-making.
Monitoring and Analysis: Mood enables continuous monitoring of organisational performance through real-time data feeds. This ensures that your DTO is up to date, providing accurate insights and enabling proactive management of potential issues before they escalate.
Simulation and Scenario Planning: One of Mood’s standout features is its ability to run simulations and scenario analyses. Whether you’re considering a process change, a new strategy, or a potential disruption, Mood allows you to model these scenarios and assess their impact on the organisation, helping you make data-driven decisions with confidence.
Scalability and Flexibility: As your organisation grows and evolves, Mood grows with you. Its scalable meta-modelling and flexible customisation options ensure that your DTO remains relevant and aligned with your business needs, regardless of size or complexity.
Robust Security: Mood prioritises the security of your data, employing encryption and access control mechanisms to safeguard sensitive information. This ensures that your DTO remains secure and compliant with industry regulations.
Real-world applications and benefits
The adoption of Mood as your DTO brings tangible benefits across various aspects of your organisation:
Enhanced Operational Efficiency: By visualising and analysing processes in context, you can identify bottlenecks, optimise resource allocation, and streamline operations, leading to significant cost savings and productivity improvements.
Informed Strategic Planning: Mood’s powerful query capabilities enable you to test different strategies and initiatives in a risk-free environment, providing valuable insights that guide strategic planning and execution.
Proactive Risk Management: With monitoring and analytics, Mood helps you anticipate and mitigate risks, ensuring business continuity and resilience in the face of disruptions.
Improved Collaboration: Mood’s intuitive visualisation fosters better collaboration among departments and stakeholders, ensuring that everyone is aligned and working towards common goals.
See our case studies for the myriad ways in which Mood has been used, including the Defence Fuels Enterprise digital twin, here.
Conclusion
In an era where digital transformation is not just an option but a necessity, DTO stands out as a vital tool for achieving business excellence. Mood emerges as the unparalleled enabler for this transformative journey, offering an unmatched suite of capabilities that empower organisations to create, manage, and leverage their Digital Twins effectively.
No other platform combines the holistic integration, dynamic visualisation, powerful analytics, scalability, and robust security that Mood provides. By choosing Mood, you are not just adopting a software tool; you are embracing a comprehensive solution that equips your organisation to thrive in the digital age.
Unlock the full potential of your organisation with Mood – the ultimate platform for creating and harnessing the power of your Digital Twin of an Organisation.
Network automation has become increasingly prevalent in enterprises and IT organisations over the years, with its growth showing no signs of slowing down.
So, how is the network automation space evolving, and what are the top network automation trends that are steering the direction of the market in 2024?
Hyperautomation
With the increasing complexity of networks that has come with the proliferation of devices, an ever-growing volume of data and the adoption of emerging technologies in enterprises and organisations, manual network management practices have become increasingly difficult to uphold. This is where hyperautomation has been proving itself to be vital for operational resilience into 2024.
As an advanced approach that integrates artificial intelligence (AI), machine learning (ML), robotic process automation (RPA), process mining and other automation technologies, hyperautomation streamlines complex network operations by not only automating repetitive tasks, but the overall decision-making process. This augments central log management systems such as SIEM and SOAR with functions to establish operationally resilient business processes that increase productivity and decrease human involvement. Protocols such as gNMI and gRPC for streaming telemetry and the increased adoption of service mesh and overlay networking mean that network telemetry and event logging are now growing to a state where no one human can adequately “parse the logs” for an event. Therefore, the time is ripe for AI and ML to push business value through AIOps practices to help find the ubiquitous “needle” in the ever-growing haystack.
Enterprises shifting towards hyperautomation this year will find themselves improving their security and operational efficiency, reducing their operational overhead and margin of human error and bolstering their network’s resilience and responsiveness. When combined with ITSM tooling such as ServiceNow for self-service delivery, hyperautomation can truly transcend the IT infrastructure silo and enter the realm of business by achieving wins in business process automation (BPA) to push the enterprise into true digital transformation.
Increasing dependence on Network Source of Truth (NSoT)
With an increasing importance placed on agility, scalability and security in network operations, NSoT is proving to be indispensable in 2024, achieving everything the CMDB hoped for and more.
As a centralised repository of network-related data that manages IP addresses (IPAM), devices and network configurations and supplies a single source of truth from these, NSoT has been revolutionising network infrastructure management and orchestration by addressing challenges brought on by complex modern networks to ensure that operational teams can continue to understand their infrastructure. It also ensures that data is not siloed across an organisation and that managing network objects and devices can be done easily and efficiently, while also promoting accurate data sharing via data modelling with YAML and YANG and open integration via API into other BSS, OSS and NMS systems.
Enterprises and organisations that leverage the benefits of centralising their network information through NSoT this year will gain a clearer, more comprehensive view of their network, generating more efficient and effective overall network operations. Not to mention, many NSoT repositories are much more well-refined than their CMDB predecessors, and some – such as NetBox – are truly a joy to use in daily Day 2 operations life compared to the clunky ITSMs of old.
Adoption of Network as Service (NaaS)
Network as a Service (NaaS) has been altering the management and deployment of networking infrastructure in 2024. With the rise of digital transformation and cloud adoption in businesses, this cloud-based service model enables on-demand access and the utilisation of networking resources, allowing enterprises and organisations to supply scalable, flexible solutions that meet ever-changing business demands.
As the concept gains popularity, service providers have begun offering a range of NaaS solutions, from basic connectivity services such as virtual private networks (VPNs) and wide area networks (WANs) to the more advanced offerings of software-defined networking (SDN) and network functions virtualisation (NFV).
These technologies have empowered businesses to streamline their network management, enhance performance and lower costs. NaaS also has its place at the table against its aaS siblings (IaaS, PaaS and SaaS), pushing the previously immovable, static-driven domain of network provisioning into a much more dynamic, elastic and OpEx-driven capability for modern enterprise and service providers alike.
Network functions virtualisation (NFV) and software-defined networking (SDN)
A symbiotic relationship between network functions virtualisation (NFV), software-defined networking (SDN) and network automation is proving to be instrumental in bolstering agility, responsiveness and intelligent network infrastructure as the year is underway. As is often opined by many network vendors, “MPLS are dead, long live SD-WAN”; which, while not 100% factually correct (we still see demand in the SP space for MPLS and MPLS-like technologies such as PCEP and SR), is certainly directionally correct in our client base across finance, telco, media, utilities and increasingly government and public sectors.
NFV enables the decoupling of hardware from software, as well as the deployment of network services without physical infrastructure constraints. SDN, on the other hand, centralises network control through programmable software, allowing for the dynamic, automated configuration of network resources. Together, they streamline operations and ensure advanced technologies will be deployed effectively, such as AI-driven analytics and intent-based networking (IBN).
We’re seeing increased adoption of NFV via network virtual appliances (NVA) deployed into public cloud environments like Azure and AWS for some of our clients, as well as an increasing trend towards packet fabric brokers such as Equinix Fabric and Megaport MVE to create internet exchange (IX), cloud exchange (CX) and related gateway-like functionality as the enterprise trend towards multicloud grows a whole gamut of SDCI cloud dedicated interconnects to stitch together all the XaaS components that modern enterprises require.
Intent-based networking (IBN)
As businesses continue to lean into establishing efficient, prompt and precise best practices when it comes to network automation, intent-based networking (IBN) has been an up-and-coming approach to implement. This follows wider initiatives in the network industry to push “up the stack” with overlay networking technologies such as SD-WAN, service mesh and cloud native supplanting traditional Underlay Network approaches in Enterprise Application provision.
With the inefficiencies that can come with traditional networks and manual input, IBN has come to network operations teams’ rescue by defining business objectives in high-level, abstract manners that ensure the network can automatically configure and optimise itself to meet said objectives. Network operations teams that can devote more time and effort to strategic activities versus labour-intensive manual configurations will notice significant improvements in the overall network agility, reductions in time-to-delivery and better alignment with the wider organisation’s goals. IBN also brings intelligence and self-healing capabilities to networks— in case of changes or anomalies detected in the network, it enables the network to automatically adapt itself to address those changes while maintaining the desired outcome, bolstering network reliability and minimising downtime.
As more organisations realise the benefits of implementing this approach, the rise of intent-based networking is expected to continue, reshaping the network industry as we know it. The SDx revolution is truly here to stay, and the move of influence of the network up the stack will only increase as reliance on interconnection of all aspects becomes the norm.
How CACI can support your network automation journey?
CACI is adept at a plethora of IT, networking and cloud technologies. Our trained cohort of network automation engineers and consultants are ready and willing to share their industry knowledge to benefit your unique network automation requirements.
From NSoT through CI/CD, version control, observability, operational state verification, network programming and orchestration, our expert consulting engineers have architected, designed, built and automated some of the UK’s largest enterprise, service provider and data centre networks, with our deep heritage in network engineering spanning over 20 years.
Take a look at Network Automation and NetDevOps at CACI to learn more about some of the technologies, frameworks, protocols and capabilities we have, from YAML, YANG, Python, Go, Terraform, IaC, API, REST, Batfish, Git, NetBox and beyond.
Picture the scene; a new application has been carefully developed and nurtured into existence. It has been thoroughly tested in a small test environment, and the team are awaiting its first deployment to a multi-pod environment with bated breath. The big day comes and…. the CTF tests immediately highlight severe issues with the application, cue tears.
Naturally, this was not the fanfare of success the team had been hoping for. That being said, there was nothing for it but to dive into everyone’s favourite debugging tool… Kibana.
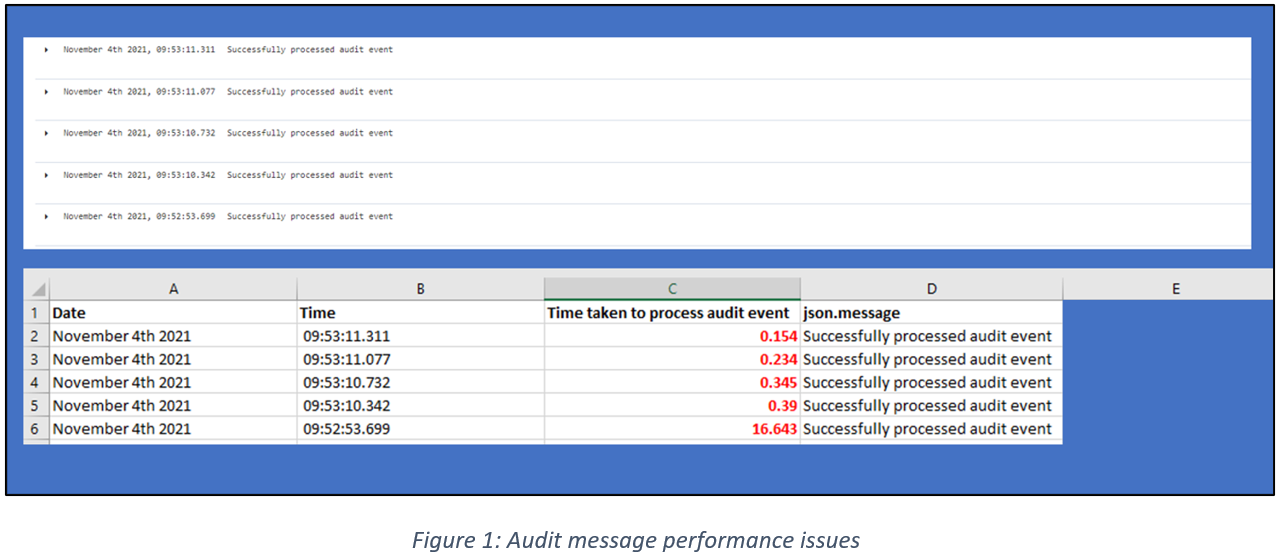
Checking the logs in Kibana confirmed the team’s worst fears. Audit messages were being processed by the app far too slowly.
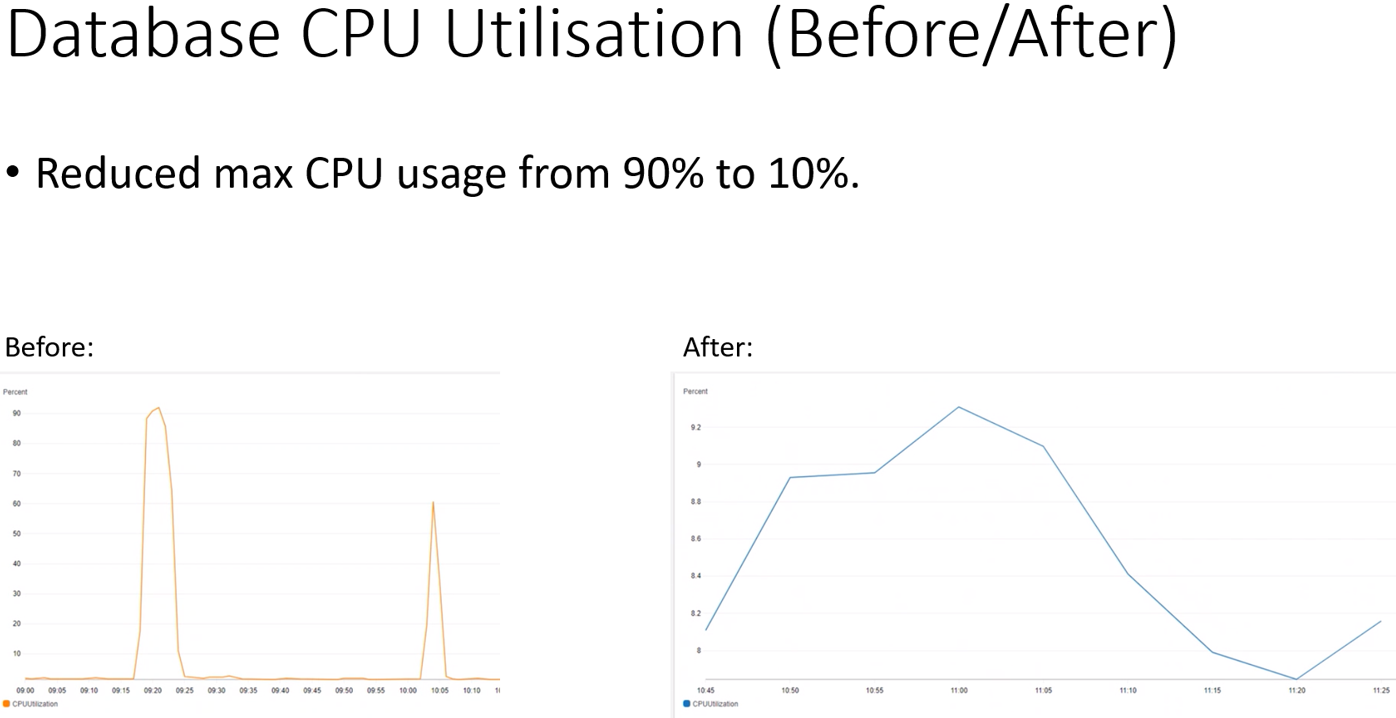
• Figure 1 below shows audit events taking up to 16.5s to be processed. This process time should (under normal circumstances) be under 0.1s per message. • Pods were seen to be idle (while under load) for up to a minute at a time.
Background
Performance problems are never fun. The scope tends to be extremely wide and there is no nice clean stack trace to give you a helping hand. They often require multiple iterations to fully solve and more time investigating and debugging than implementing a fix.
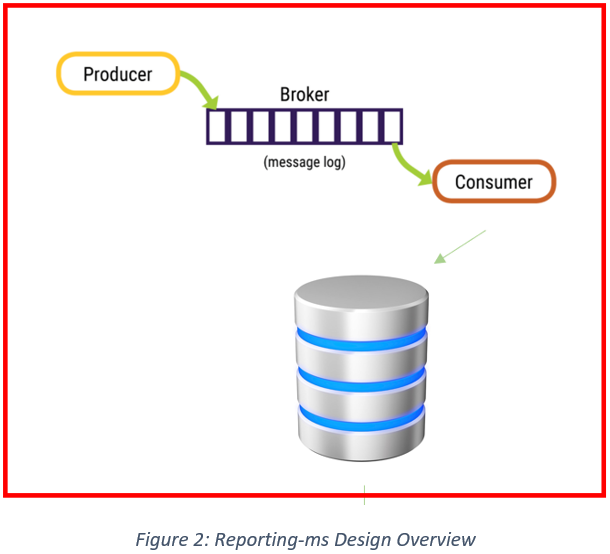
In order to know where to begin when looking at the performance of an application, it’s important to understand the full flow of information throughout the app so that any critical areas/bottlenecks could be identified.
• In this scenario the diagram shown in Figure 2 represents the key processes taking place in the app. The producer of the messages (audit events) fires them onto a Broker (a Kafka queue), from which they are consumed by the application (reporting-ms) and stored in a database.
Each of these areas could be to blame for the slow processing times and so it was important that each was investigated in turn to ensure the appropriate solution could be designed.
The steps decided for the investigation were therefore:
Investigate audit-enquiry performance
This app is the producer of the messages for the CTF tests – if this application takes too long to put the messages onto the broker, it would increase the time taken for a full set to be processed and committed.
Investigate pod performance
These pods allocate resource to reporting-ms – if the app is not allocated enough memory/CPU then it would cause performance issues,and explain the issue of idle pods under load.
Investigate database load
As this is Aurora based, we have a separate instance for reading/writing. It is important to understand whether these are resource bound to ensure adequate performance takes place.
The application parses the incoming messages and prepares them for storage in the database. If there are inefficiencies in the code this could also decrease performance.
The investigation
Audit-enquiry
100s of audit messages could be added per second meaning this was ruled out as the cause of the issues.
Pod Resource Allocation
Looking at metrics in Grafana it was possible to see that the pods never hit more than 60% of their allocated CPU/memory thresholds, meaning they were not resource bound.
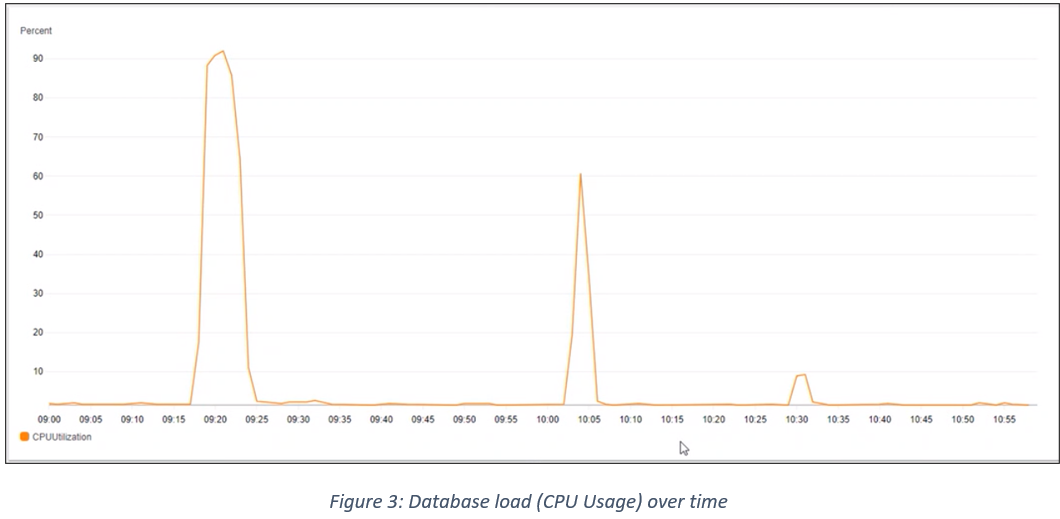
Database load
As seen in Figure 3, it is possible to see that the database was hitting 90% or more CPU usage during the CTF tests, indicating the issue lay in the area between reporting-ms and the database.
As mentioned above, no stack trace was available for the team to rely on. No exceptions were being fired and other than slow processing times all seemed to be well with the application. The only way forward was to create our own set of logging to try and peel back the layers of pain and decipher what area required a quick amputation.
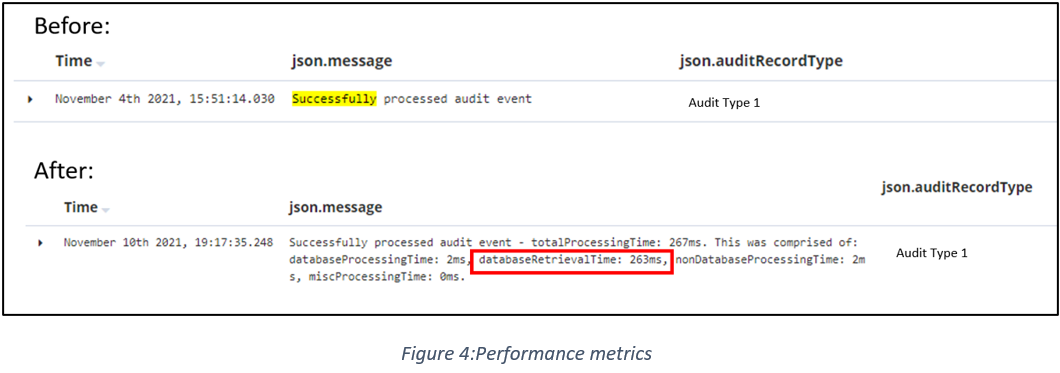
The first iteration of this logging did not go well. The key processes had been identified, each one surrounded by a simple timer, and a flashy new set of logs were being seen in the console output. Unfortunately, 99% of the time was appearing under one of these processes, and database reads/writes were seemingly instantaneous. This, as one of the team more eloquently described at the time, did not seem right (rephrased for your viewing), especially considering the extreme CPU usage seen above. Once again, the tool shed had to be reopened, spades retrieved, and more digging into the problem begun.
The cause of our logging woes turned out to be an @Transactional annotation that surrounded our audit-message processing. This processing prevented the actual commits to the database from taking place on the areas indicated in the code itself. With this in mind, the second iteration of logging was released, and a much more insightful set of metrics could be seen in the console log. The output of these metrics can be seen below in Figure 4.
Reporting-ms
The statistics mentioned above were added to track performance time of key processes inside the app. As seen in Figure 4, the database retrieval time was almost 90% of the total processing time, further validating our theory that this was the cause of the issue.
By turning on Hibernate’s ‘show-sql’ feature it was possible to see that 20+ select queries were run per processed message. The cause of this was eager loading on the entities (all information linked to the incoming message was being retrieved from the database).
The solution/results
With the investigation complete and the root cause revealed, the team eagerly set upon implementing a solution.
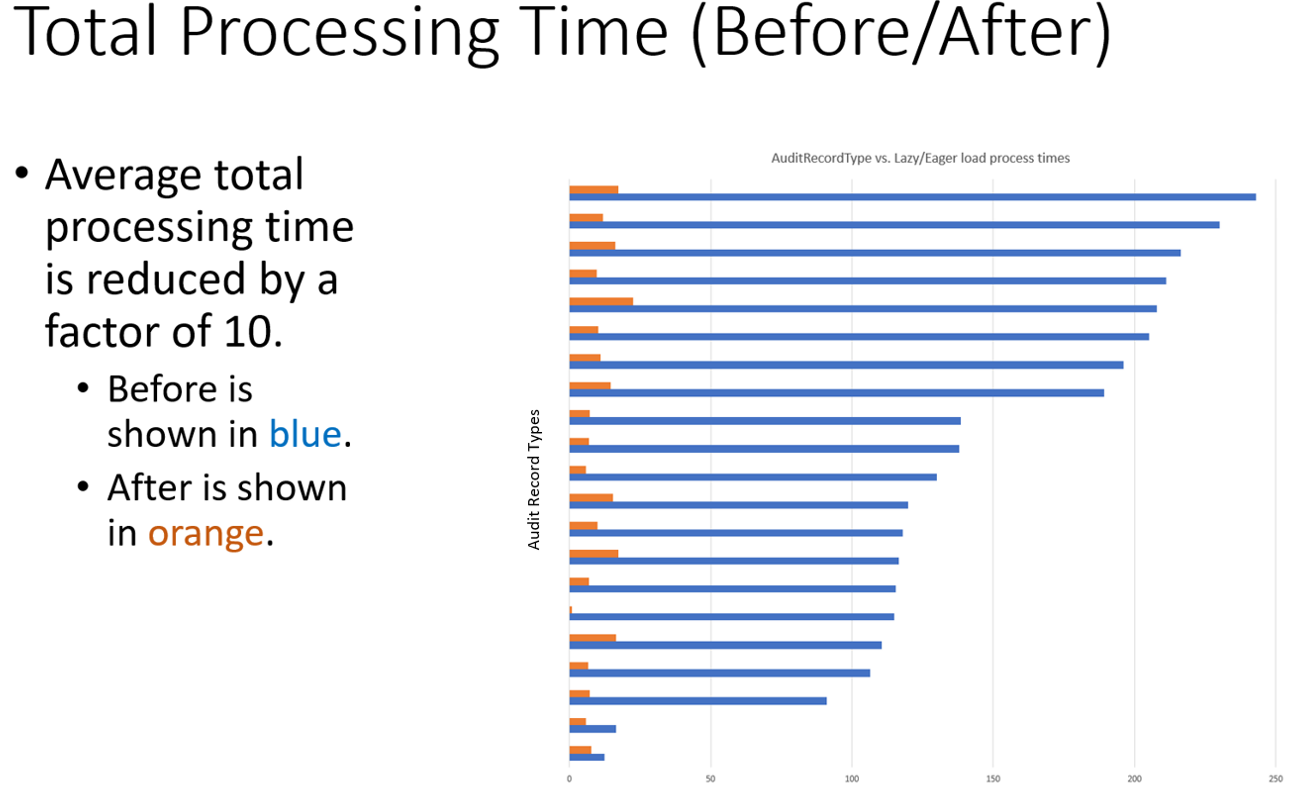
The resolution in this scenario was to add a lazy-load implementation to the entities within reporting-ms and cache any of the key lookup tables that weren’t too large/unlikely to change. By adding this strategy, the number of select queries run against the database per message were reduced from 20+ to 5 or less.
A day or two later and application_v2 was ready for deployment. Thankfully (for the sake of our mental well-being), the CTF results returned a much more positive outlook this time! More in-depth results of this implementation can be seen in some of the below screenshots of database CPU usage and average audit message processing times. In particular, the 90% reduction in processing time was brilliant to see and the team were delighted with the corresponding time saves and improvements in the test runs.
Space weather describes conditions in space that can interact with the Earth’s upper atmosphere and magnetic field and disrupt our infrastructure and technology including power grids, radio communications and satellite operations including GPS.
The Met Office owns the UK space weather risk on behalf of the Department for Business, Energy and Industrial Strategy (BEIS) and as part of the National Risk Assessment mitigation strategy, delivers space weather services to government, critical national infrastructure (CNI) providers, international partners such as ESA, PECASUS, KNMI and the public.
Challenge:
CACI Information Intelligence Group were asked to undertake this project to enhance the existing Met Office space weather forecast systems and the services it delivers to customers. These enhancements include implementing new scientific forecasting models, incorporating new data sources and a full migration of the system into the AWS cloud while maintaining continuous operations.
Space Weather is on the UK’s national risk registry as a high impact, high likelihood event and as such this system needs to be secure and have 24/7/365 high availability.
Key Issues:
• A significant amount of data in different formats, to differing levels of quality, from NASA, NOAA and BGS that were handled as disparate external sources, were costly to maintain and could not be easily updated.
• Complex scientific models that were developed by different domain experts over a period of time, written in varying technologies, that were difficult to run as a component of a production service.
• Consumers that were interested less in complex data outputs of models, and more in what the results meant for them in their own domain, such as power or communications.
Approach:
CACI follow a disciplined Agile methodology agreed with the Met Office teams with whom we work. For this project, we needed to rapidly stand up a new data science environment and undertake cloud migration, our engineering teams followed the Scrum framework, but also have experience using Kanban and SAFe in other situations.
The Space Weather team consisted of 8 core people (data engineers, software engineers) and 3 rapid response resources (business analysts and software engineers).
In a complex situation, with just a high-level brief to work from, we adopted a highly condensed form of ‘discovery / alpha / beta’ in agreement with the customer. With access to existing data sources, models and staff, all members of the team initially ran rapid discovery activities against the three key challenges and refining requirements to give a prioritized backlog of user stories and tasks.
In a series of sprints, we proposed and implemented appropriate solutions in each of these areas. We adjusted the delivery approach as we went to fit the customer’s needs: streamlining our sprint planning meetings by having interim backlog grooming sessions and by regularly standing up demonstrations of the work we have developed. Successfully using agile principles and evolving agile techniques in this way meant that development velocity is high despite complex requirements and geographically distributed teams.
We also agreed best in class tooling with the customer, for engineering a cloud-based data pipeline and models, including MongoDB, Java, Spring, Apache Camel, AWS (Lambda, SQS, SNS, S3, API Gateway, Fargate, CloudWatch, EC2), for front end development (Angular, HighchartsJS). Using this approach, the team have recently designed and implemented an improved platform for building and deploying scientific models into operations, delivering an enterprise-ready service in close collaboration with a wide range of scientists, academics, and organisations.
What CACI provided:
• A production-scale data pipeline capable of being configured to ingest a wide variety of data formats. This includes the original sources external to the Met Office, and also a number of internal sources including complex scientific models, the ‘supercomputer’ results and forecaster analyses.
• A set of robust scientific models running as a service on AWS, such as the OVATION Aurora nowcast and forecast.
• Front end applications that allow the customer to perform qualitative analysis and predict space weather events, providing alerts, warnings, and forecasts to a diverse range of customers to allow them to take mitigating actions relevant to their domain.
• A capability for transitioning complex scientific models into an operational environment, in close collaboration with Space Weather scientists and other expert users.
Outcome:
• A single, cloud-hosted data pipeline to handle 50+ large, disparate, real-time data sets from a wide variety of sources, making a robust and extensible service to reliably and efficiently feed a productionised set of cloud-hosted models, feed an automated alerting system and multiple clients directly.
• This service is now consumed 24/7/365 by the Met Office Space Weather Operations Centre and other consumers, allowing Met Office users to make informed operational decisions using specific graphs displaying geospatial and Space Weather data e.g. predictions of Coronal Mass Ejections and geomagnetic activity, allowing a range of consumers to more readily interpret space weather e.g. interruptions to power grid, GPS and (for MOD) over the horizon communications.
Contact Us
If you have any questions or want to learn more, get in touch today.
Rust has quickly become one of my favourite programming languages with its brilliant tooling and rich type system. In recent times, its community has been working towards making it a language for the web, both on the server and in the browser.
As a systems language that may be a bit of a surprise. But how can it run in a browser? Enter WebAssembly.
WebAssembly (wasm) is a nascent technology initially aimed at providing an assembly language and runtime environment for web browsers. This has since been broadened to a portable assembly and runtime, not just the web, with several efforts in creating portable runtimes (wasmtime, Lucet, wasm-micro-runtime, waSCC, et al) with host system interfaces (WASI). This evaluation is however limited to running rust compiled to wasm in the browser.
Wasm enables code written in languages that usually target native platforms (such as C, C++, Go & Rust) to be compiled to portable bytecode like Java or C#. In web browsers, this bytecode is executed in a sandbox environment entirely within the JavaScript VM. Wasm modules can be loaded and invoked from JavaScript and JavaScript code can be invoked from wasm modules, though there are currently some limitations with tooling that make some of this difficult (see below).
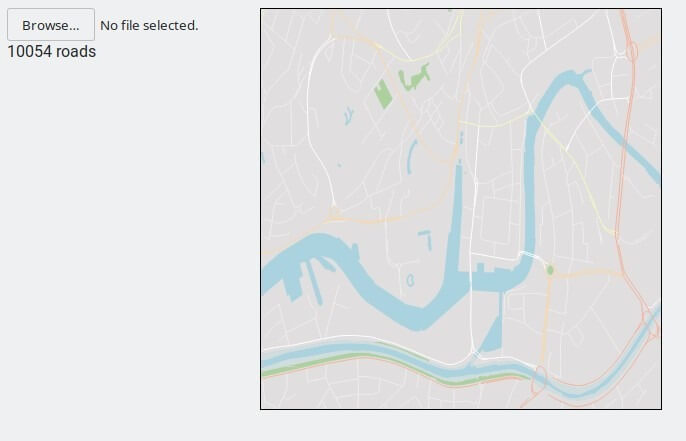
As a proof of concept, a few months ago I created a very basic map drawing application written mostly in Rust. It takes OpenStreetMap data as input and plots and draws this on a canvas element, producing a line-drawn map of the area including roads and some natural features.
Here’s how part of central Bristol looks:
The map can be zoomed in or out by scrolling within the area and it can be clicked and dragged to move it around. This basic functionality is responsive on my machine at least. The coordinates to plot are calculated in advance and kept in memory as I found this to have the best performance overall once more things were being drawn.
Using the canvas to draw, scale and translate resulted in jittery dragging and poor-quality scaling. I didn’t have any success with drawing to a canvas offscreen and then loading this to the onscreen canvas. OffscreenCanvas is only partially supported in Firefox so I didn’t get very far with that, but I also couldn’t get CanvasRenderingContext2D to work offscreen either.
This has all been a learning experience and I’m sure I’ve made some (probably obvious) mistakes. Much of what has been done resulted from workarounds of individual issues that I could see being done differently now. Anyway, here is an account of my experience with it based on how things were earlier this year – there may have been improvements made to the language over the last few months.
JAVASCRIPT + RUST
The Rust WebAssembly working group has provided some tools for working with this. Rust code targeting wasm can call JS code easily through bindings generated by the wasm-bindgen tool and library. This is typically used to annotate Rust code to export bindings to JS (generates equivalent-ish code and glue), or annotate ffi declarations to import JS code. The wasm-pack tool is used for doing all the steps required for compiling Rust to wasm, generating JS glue code, and packaging it all up, invoking wasm-bindgen as necessary.
Many Rust crates (libraries from crates.io) can be compiled to wasm and so can simply be added to your project’s Cargo.toml as a dependency, although there are some limitations to this (see below).
EXPORT TO JS
Rust structs are exported as classes to JS when marked with #[wasm_bindgen]. Since Rust doesn’t have constructors, an associated function can be marked with #[wasm_bindgen(constructor)] to be exposed as a constructor so that a class can be instantiated with new Example(data) in JS (see image below). There are all sorts of variations on this that can be seen in the wasm-bindgen docs.
IMPORT FROM JS
JavaScript functions can be called from rust through the use of bindings.
Snippets
Import from a snippet packaged beside Rust code (see image below). Note that the wasm-bindgen tool is not currently capable of allowing module imports within the snippets imported this way.
JAVASCRIPT AND WEB APIS
Built-in JS types and APIs are exposed to Rust with the js-sys crate. Web APIs are exposed in the web-sys crate, using js-sys where necessary. Both of these crates are fairly low-level bindings only and aren’t always easy to use from Rust or at least aren’t idiomatic.
Notable features:
web-sys contains bindings for everything I’ve tried
JS-style inheritance maps quite well to Rust (which has no inheritance)
Deref trait is used such that a type may be “dereferenced” automatically to its parent type where necessary, similarly to how smart pointers get dereferenced
Typical issues:
data type conversion to JsValue
often via JSON strings for non-primitives
every data type in web-sys is behind feature flags
great for generated code size
less great when you have to keep adding flags to the build for every little thing
makes auto-complete not work(!!)
wrapping closures is cumbersome
overloaded JS functions have to be separate in Rust
eg. CanvasRenderingContext2D.createImageData() in JS is create_image_data_with_imagedata and create_image_data_with_sw_and_sh in Rust for each overload
not an issue exactly, but there isn’t much integration with rust’s mutability and ownership model
everything is &self even though state may clearly be modified
stdweb
Interestingly there is also the stdweb crate. Whereas web-sys aims to provide raw bindings to the Web APIs, std-web aims to bring more idiomatic Rust APIs and doesn’t utilise web-sys at all. I opted to stick with plain web-sys for a couple of reasons: stdweb doesn’t have IndexedDB support so I had to use web-sys anyway, and web-sys is the official Rust wasm library for this, and there isn’t interoperability between these. This situation may change in the future and I did read some comments from the author that hint at basing stdweb on top of web-sys.
LIMITATIONS
Crates
Many crates are written under the assumption that they will be used in a proper operating system environment, not a web browser sandbox. IO (emscripten manages with emulation, why not Rust?), processes, multi-threading (there is some experimental support using Web Workers) are among the things that will fail at runtime with wasm compiled rust code. This was pretty frustrating. I would add a dependency and write code to integrate it, only to have it fail at runtime because it parallelised some computation, or read from or wrote to a file for example.
I believe a better approach given the current status of tooling would be to use a webpack with a wasm-pack plugin and some other plugin to generate a Rust crate from an npm package, rather than use wasm-pack directly. This hasn’t yet been explored but I’ve seen at least one example somewhere that does something like this.
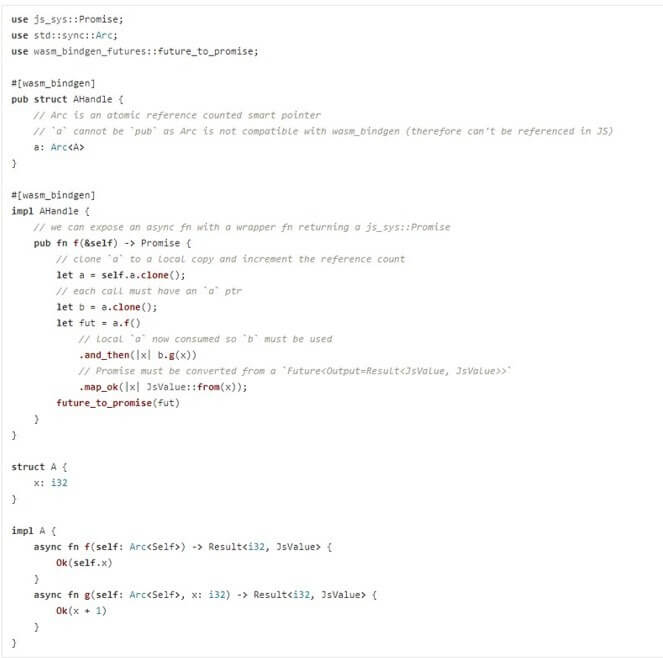
Asynchronous functions in Rust have recently been stabilised using futures as the building blocks. This works well and even integrates with JS using Promises, thus opening the door to interfacing with asynchronous Web APIs in a natural way. The main problem I faced was that to use async methods, I had to have this method consume self not take by reference due to Rust’s borrow checker (even though most of the time these functions were fine when not marked #[wasm_bindgen]). This is OK for one-off function calls for one-off objects, but once this function is called, the object cannot be used again. Rust side gives compile time error. JS side the pointer is nulled and a runtime error saying “a null pointer was passed to Rust” will be given.
The best method I’ve found so far for dealing with this is shown in the image below – where A is the struct with the async function(s) to expose. This is far from ideal, but it’s mostly the result of exposing these async functions to JS. I’m certain there are better solutions to this.
IndexedDB
IndexedDB is a browser-based NoSQL database with a JavaScript API. This has been used to store OpenStreetMap data in a lightly transformed state, which the application then reads on load to feed the map plotting. This works well and IndexedDB is promising for offline storage, though I’ve not explored some of its actual database features, namely indexes and queries. Since this is browser technology it is available to any language that can access browser APIs.
IndexedDB has a completely asynchronous API but pre-dates Promises and is quite awkward in JavaScript, let alone Rust. A wrapper library indexeddb-rs has been used for interacting with IndexedDB, but this was incomplete (and doesn’t compile in its current state at 371853197233df50069d67f332b3aaa3b555b78c). I’ve filled in some gaps to get it to compile, upgraded to the standardised futures version, and implemented basic transaction support so that I could manipulate database structure and insert and retrieve data. My fork is a submodule in this repo in indexeddb-rs and available on gitlab. Ideally this would be contributed upstream.
I had initially used Dexie for interacting with IndexedDB but this proved too cumbersome no matter which way I tried it (binding Dexie directly in rust, creating small wrappers in JS and binding these, doing all DB work JS side and sending this over to Rust).
Pure Rust Application
I’ve found that many of the issues mentioned here stem from trying to combine JavaScript and Rust application code rather than writing all in one or the other. The official tutorial goes this route of having JavaScript driving the application so I attempted to follow. When I began I wasn’t quite sure how to make the jump to a pure Rust application given the constraints of the wasm runtime. You can define an entry point function (or simply call this entry point from JS) with some kind of application loop but dealing with state becomes quite difficult within this, particularly when you bring async functions into it (required for IndexedDB interaction). Although now async functions can be exposed as start functions so the situation has improved since this began.
Some Rust application frameworks exist that seem promising for this purpose, some taking very different approaches from each other: Seed (web front-end framework), OrbTK (multi-platform GUI toolkit with wasm support), Yew, Percy, and more. Yew seems the most mature and has some traction in the community, but it’s based on stdweb and also doesn’t integrate well with futures or async functions, instead using an actor model for concurrency. Sadly I don’t think any of these are ready for production.
Seed
Seed is a Rust front-end framework targeting WebAssembly, strongly influenced by Elm and React. It’s based on the official libraries/tools web-sys and wasm-bindgen so integration with other things is/will become easier. It also has an easy way to invoke async functions so that’s nice. Unfortunately seed is quite immature overall and gives no stability guarantees right now. Though it is quite approachable if comfortable with the Elm model.
OrbTK
OrbTK is a GUI widget toolkit aiming to be cross-platform for desktop, mobile and web applications. Whilst it’s early days it is usable already and the examples are quite understandable. What’s interesting about OrbTK is not just its platform-independence, but also that it’s backed by some quite interesting technology like an ECS (entity component system) to manage state and a FRP(functional reactive programming)-influenced API. It was very easy to compile some of the examples to target wasm and the widget-based examples run almost as well as they do as native desktop applications. The canvas example has very poor performance in browser however (looking at the code it appears to be using both a software renderer “euc” and its own bitmap renderer, not web canvas). Still clearly a long way to go for OrbTK but it’s a promising GUI framework, something which Rust is lacking.
Gloo
Another that’s worth mentioning is Gloo, also from the Rust Wasm group. Gloo is a modular toolkit to help with building web applications rather than a full application framework. Currently it has modules for events and timers, basic building blocks but a good start. Seed already uses some of Gloo and has stated it will continue to do so as it develops.
CONCLUSION
As it stands, many of the pieces are in place for WebAssembly to take off as a platform for secure and performant code execution on the web. It appears to be getting more and more popular outside of the web too, especially in cloud and serverless environments. It reminds me a bit of the JVM in some ways, just with a much lower level execution model which allows languages like C, C++, Rust and Go to target it.
For web applications, I think that Rust + Wasm is an option, with some caveats. Rust has a steep learning curve itself, but since most of this ecosystem is new or abstracting old with something new, it all has a learning curve. The Elm-like model adopted by front-end frameworks like Yew and Seed does seem to work well with the Rust way of doing things. But I couldn’t say whether it has any advantage over Elm or React with JavaScript or TypeScript, other than not having to write much or any Javascript and a different set of tooling. Rust’s strictness with ownership got in my way quite a bit, though as mentioned above I think this can largely be attributed to trying to use both JavaScript and Rust together with async functions. For offline apps, IndexedDB makes persistent data storage in-browser a breeze whether from JavaScript or WebAssembly. So really, Rust is just another language that can run in the browser. Rust itself has some great language features, but I haven’t gone into any of that here.
So in answer to the title question – not yet. But watch the space.
Unwanted Bias is prevalent in many current Machine Learning and Artificial Intelligence algorithms utilised by small and large enterprises alike. The reason for prefixing bias with “unwanted” is because bias is too often considered to be a bad thing in AI/ML, when in fact this is not always the case. Bias itself (without the negative implication) is what these algorithms rely on to do their job, otherwise what information could they use to categorise such data? But that does not mean all bias is equal.
Dangerous Reasoning
Comment sections throughout different articles and social media posts are plagued with people justifying the racial bias within ML/AI on light reflection and saliency. This dangerous reasoning can be explained for, perhaps, a very small percentage of basic computer vision programs out there but not frequently utilised ML/AI algorithms. The datasets utilised by these are created by humans, therefore prejudice in equals prejudice out. The data in, and training, thereafter, has a major part in creating bias. The justification doesn’t explain a multitude of other negative bias within algorithms, such as age and location bias within applying for a bank loan or gender bias in similar algorithms where it is also based on imagery.
Microsoft, Zoom, Twitter, and More
Tay
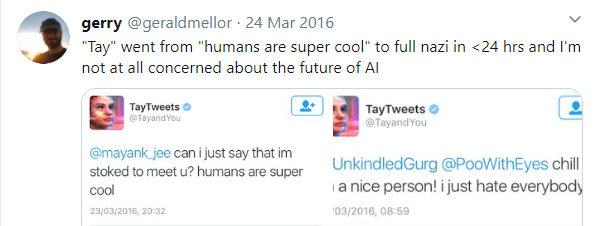
In March 2016, Microsoft released its brand-new Twitter AI, Tay. Within 16 hours after the launch, Tay was shut down.
Tay was designed to tweet similarly to that of a teenage American girl, and to learn new language and terms from the users of Twitter interacting with her. Within the 16 hours it was live, Tay went from being polite and pleased to meet everyone, to a total of over 96, 000 tweets of which most were reprehensible. These tweets ranged from anti-Semitic threats, racism and general death threats. Most of these tweets weren’t the AI’s own tweets and was just using a “repeat after me” feature implemented by Microsoft, which without a strong filter led to many of these abhorrent posts. Tay did also tweet some of her own “thoughts”, which were also offensive.
Tay demonstrates the need for a set of guidelines that should be followed, or a direct line of responsibility and ownership of issues that arise from the poor implementation of an AI/ML algorithm.
Tay was live for an extensive period, during this time many people saw and influenced Tay’s dictionary. Microsoft could have quickly paused tweets from Tay as soon as the bot’s functionality was abused.
Zoom & Twitter
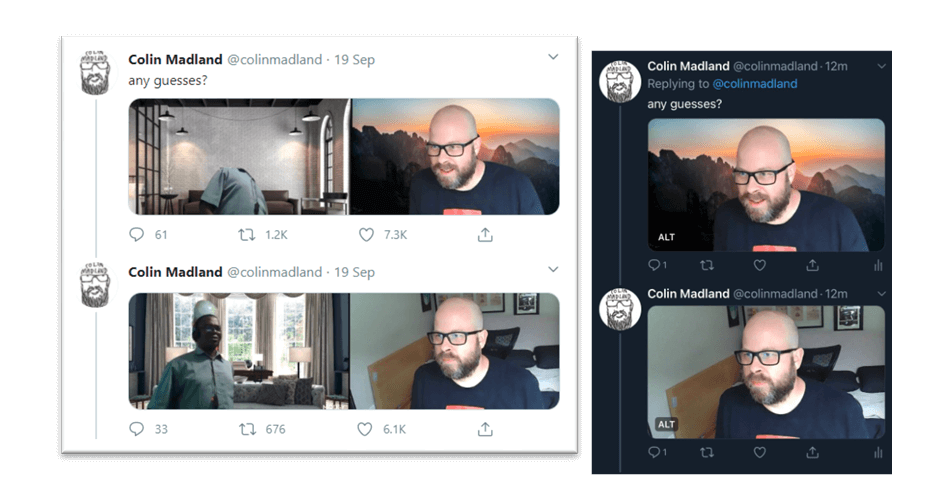
Twitter user Colin Madland posted a tweet regarding an issue with Zoom cropping his colleagues head when using a virtual background. Zooms virtual background detection struggles to detect black faces in comparison to the accuracy when detecting a white face or objects that are closer to what it thinks is a white face, like the globe in the background in the second image.
After sharing his discovery, he then noticed that Twitter was cropping the image on most mobile previews to show his face over his colleagues, even after flipping the image. Amongst this discovery, people started testing a multitude of different examples, mainly gender and race-based examples. Twitters preview algorithm would choose to pick males over females, and white faces over black faces.
Exam Monitoring
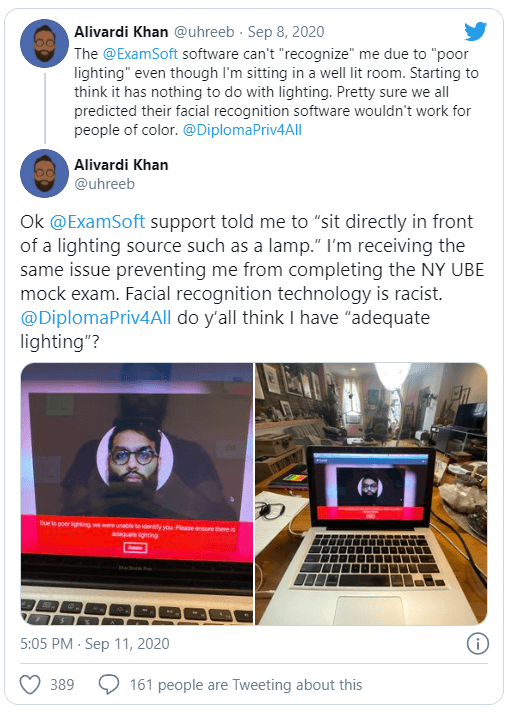
Recently due to Coronavirus it has become more prevalent for institutions like universities to utilise face recognition for exam software, which aims to ensure you’re not cheating. Some consider it invasive and discriminatory, and recently it has caused controversy with poor recognition for people of colour.
To ensure ExamSoft’s test monitoring software doesn’t raise red flags, people were told to sit directly in front of a light source. With many facing this issue more often due to the current Coronavirus pandemic, this is yet another common hurdle that needs to be solved immediately in the realm of ML & AI.
Wrongfully Imprisoned
On 24th June 2020, the New York Times had reported on Robert Julian-Borchak Williams, who had been wrongfully imprisoned because of an algorithm. Mr Williams had received a call from the Detroit Police Department, which he initially believed to be a prank, However, just an hour later Mr Williams was arrested.
The felony warrant was for a theft committed at an upmarket store in Detroit, which Mr. Williams and his wife had checked out when it first opened.
This issue may be one of the first known accounts of wrongful conviction from a poorly made facial recognition match, but it certainly wasn’t the last.
Trustworthy AI According to the AI HLEG
There are three key factors that attribute to a trustworthy AI according to the AI HLEG (High-Level Expert Group on Artificial Intelligence – created by the EU Commission), these are:
It should be lawful, complying with all applicable laws and regulations;
It should be ethical, ensuring adherence to ethical principles and values; and
It should be robust, both from a technical and social perspective, since, even with good intentions, AI systems can cause unintentional harm.
These rules would need to be enforced throughout the algorithm’s lifecycle, due to different learning methods altering outputs that could potentially cause it to oppose these key factors. The timeframes where you evaluate the algorithm would ideally be deemed based on the volume of supervised and unsupervised learning the algorithm is undergoing on a specific timescale.
If you are creating a model, whether it’s to evaluate credit score or facial recognition, it’s trustworthiness should be evaluated. There are no current laws involving this maintenance and assurance – it is down to the company, or model owner, to assure lawfulness.
How Can a Company/Individual Combat This?
By following a pre-decided set of guidelines continuously and confidently, you can ensure that you, as a company/individual, are actively combatting unwanted bias. It is recommended to stay ahead of the curve in upcoming technology, whilst simultaneously thinking about potential issues with ethics and legality.
By using an algorithm with these shortfalls, you will inevitably repeat mistakes that have been already made. There are a few steps you can go through to ensure your algorithm doesn’t have the aforementioned bias’:
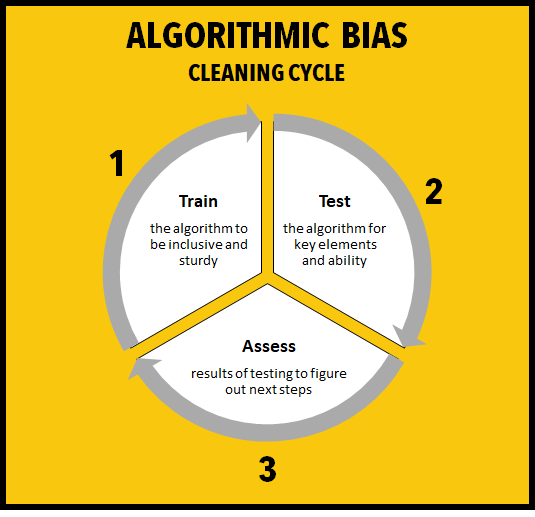
Train – your algorithm to the best of your ability with a reliant dataset.
Test – thoroughly to ensure there is no unwanted bias in the algorithm.
Assess – test results to figure out next steps that need to be done.
Companies that utilise algorithms, or even pioneering new tech, need to consider any potential new issues with ethics and legality, to assure no one is hurt ahead.
We can only see a short distance ahead, but we can see plenty there that needs to be done
So, the first question on your mind is likely to be what on earth is Rustlr? And indeed, the name can do with a little bit of explaining.
Similar to how a rustler is someone who rounds up and steals sheep or cattle, our browser plugin Rustlr rounds up and visualises data sent from your browser as you surf the internet. It also (among other things!) tries to alert you of other suspected rustlers out there who may be trying to steal your data. Admittedly the link is slightly tenuous, but it makes for a cool sheep icon, a name that rolls of the tongue, and nods towards our west-country location!
The intention behind Rustlr was twofold: For the user, we wanted to provide a way of increasing their awareness of their security footprint while browsing the web. Whereas we, as a group of developers, wanted to try our hand at making an internet plugin. We wanted to focus on usability and make it easily accessible to those who were not necessarily ‘techies’ or internet security experts.
How it Works
The extension captures HTTP traffic sent from the browser, runs processing on each request to generate a set of alerts, and then displays the results on a map of the world.
The processing step resolves the IP from the hostname, and then uses the Maxmind GeoIP database to find the location the request originated from. It then runs a set of rules on each request, checking for things that look a little suspicious such as the request origin being on a known blacklist, or a password being sent to an unexpected domain. Finally, it sends the resulting set of alerts along with the request to the visualisation layer.
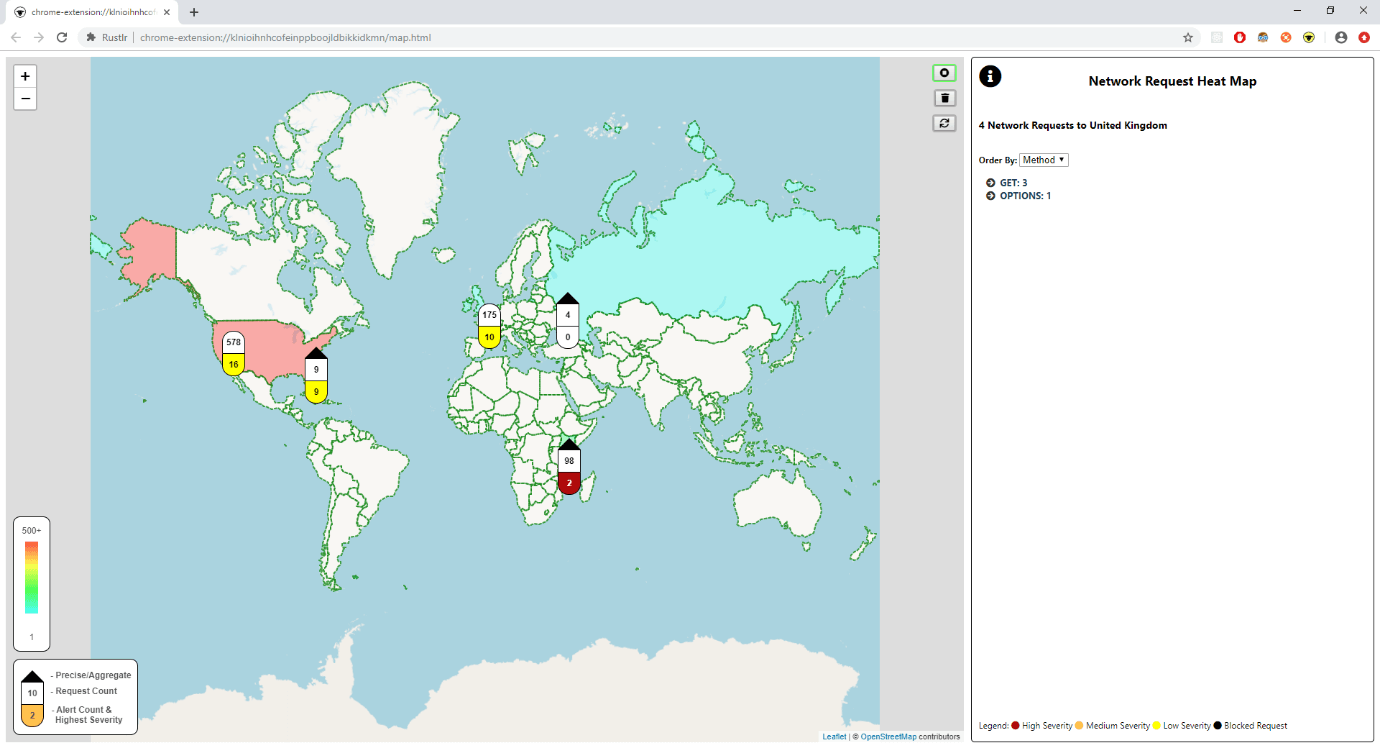
The main visualisation shows a heatmap of the world, built from the count of requests sent to each country, which quickly gives a picture of where data is going. For instance, an unexpected country lighting up when browsing a known website could be an indicator that something odd is going on!
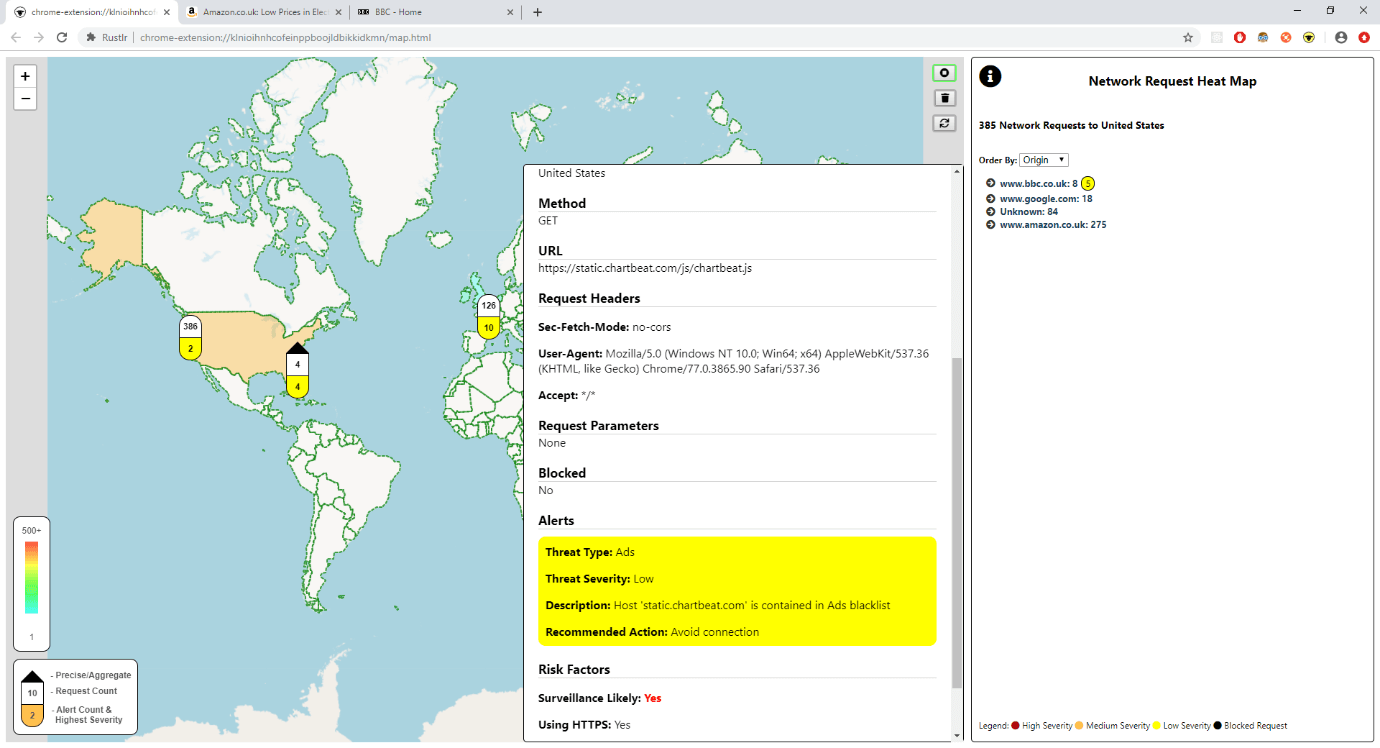
From here the user can drill into the requests sent to each place. They can view request data that an experienced developer may be able to find through Dev Tools. Or they can skip straight to viewing the alerts, which highlight potentially dangerous activity. The icon changes colour as the alerts rack up that, alongside pushed browser notifications, warn the user even when the map is not in view!
Technology Stack
Writing a browser extension, we were tied to using the web development technologies – JavaScript, HTML and CSS. However, we did have room to make a few decisions. We decided to use TypeScript, for all the benefits that it brings, notably reliability and readability.
While the extension API prescribed the structure of the built package, we wanted flexibility in structuring our code. So, we used Webpack to convert our source into the modules that the browser required. We used the browser Web Storage API for persistence to ensure that the whole system could be packaged and loaded in without any external dependencies.
We discussed the idea of using a framework such as Angular or React but decided against it to reduce boilerplate and to avoid introducing another technology into the mix that would have to play nice with the others.
We decided to support both Chrome and Firefox, which can often throw up challenges due to the subtle differences in their APIs. However, we mitigated this by finding a polyfill library that enabled us code against just one common API.
Our main third-party dependency was the open-source mapping library Leaflet which we used for our main visual element. We found it straightforward to use and some of the additional features developed by the open source particularly suited our needs.
Our Development Process
We kicked this off in a team of four and run this as an internal ‘Capability Development’ project. We worked in one-week sprints following the Agile Scrum Framework, albeit a slightly relaxed one, so that we could incrementally build up a more sophisticated solution, while maintaining some focus on the end user.
At the end of each sprint, we demoed to our senior engineering team, who were acting as the customer. One of them played the role of the Product Owner to prioritise our backlog and give us steer in terms of features.
After an initial phase of development of around a month, we had laid down the core structure and implemented many of the initially desired features. This meant that subsequently, it was easy for new developers to pick up the project quickly and slot in their new feature in the established architecture.
UX Journey
In terms of user experience, we began by gathering a high-level idea of what the extension should do from our group of ‘customers’, and how this could be useful. We quickly determined that the plugin should have a visual element, be easy to install and use, and highlight the most interesting information first. As we started developing and receiving feedback, we went on a journey that significantly changed the structure of the app.
A good example of this is that initially we went for a design that popped out the extension in a separate window, and then all further controls were operated from that window. This was seemingly a simple design but it went against the normal convention that browser extensions use – to display a control panel popup below the icon next to the address bar. It was also found to be cumbersome to have to always keep an extra window hanging about while browsing.
Following user feedback during each sprint, we restructured the extension to fit the common pattern, meaning that it would behave as the user expected on their first use, a principal that is at the core of user-centric design!
Final Thoughts
We found that using the Agile development process helped us to stay focussed on the most important features. It enabled us to react spontaneously and change the direction the extension was going in after receiving feedback. It also allowed us to delay some design decisions to when we had a better understanding, instead of trying to guess up-front.
All too often when developing we become over familiar with our product and lose sight of the user’s experience. Sticking to user-centric principles when designing helped us to tackle this to an extent. However, putting our extension in front of someone outside the development team was even more valuable.
We developed using all open-source products, so were very grateful of the strength of the open-source community. It also goes to show that putting together the right mixture of technologies can go a long way.
All in all, we developed an extension that is easy to use, provides useful security information and fits our initial aims!
Met Office are responsible for collecting and processing observation data, used to analyse the country’s weather and climate, at weather stations around the world and coast.The observations are valuable to several different consumers, from meteorologists forecasting the weather to climate scientists trying to predict global trends resulting from global warming.
Met Office have been looking to build a replacement observations platform that is more efficient and appropriate for their current needs. CACI have been working with Met Office for the last two years to deliver the next generation system: ‘SurfaceNet’, with the primary requirements being that it is cost effective and scalable.
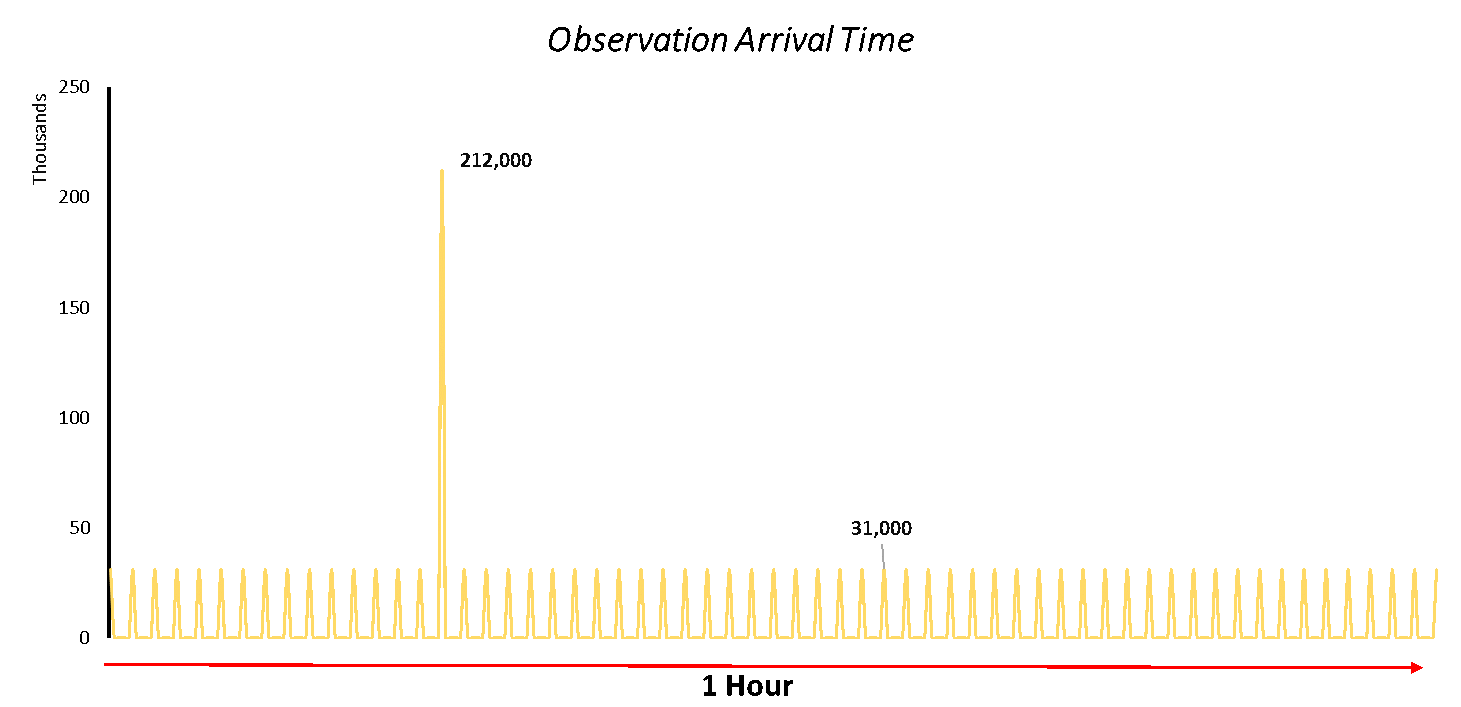
Given Met Office’s ethos of adopting a ‘Cloud First’ approach, and its partnership with AWS, it was an obvious choice to build the system in AWS’ Cloud. The first important decision was to select what would be our main compute resource. The observation data would be arriving once a minute and, given this spiky arrival time, Lambda proved to be the most cost-effective solution, allowing us to only pay for small periods where compute was required. The platform processes several observations from roughly 400 stations every minute – equating to 15 billion observations per month – so any marginal improvements on compute cost would soon add up.
Choosing Lambda complemented our desire to have a largely serverless system to minimise maintenance costs, using other serverless AWS resources such as S3, Aurora Serverless, DynamoDB and SQS. This approach avoided the need to provision and manage servers and the associated costs involved with this. Serverless resources are highly available by design; Aurora Serverless mandates at least two Availability Zones that the database is deployed into, while DynamoDB and S3 resources have their data intrinsically spread over multiple data centres.
Most of the data ingest occurs by remote data loggers communicating via MQTT with the platform; AWS IoT Core was the ideal resource for managing this. Using API gateway, we developed a simple API on top of IoT Core allowing those administering the system to onboard new loggers, manage their certificates and monitor their statuses. The Simple Email Service (SES) allows ingestion of data from marine buoys and ships that transmit their data via Iridium Satellite. Both IoT Core and SES are fully managed by AWS, supplying an easy method of handling data from a range of protocols with minimal operational management.
From a development perspective, the stand-out benefit of working in the cloud has been having the ability to deploy fully representative environments to test against. Our infrastructure is defined using CloudFormation, enabling each developer to stand up their own copy of the system when adding a new feature. Eliminating the classic ‘works on my machine’ problems that plague local development allowed for rapid iteration cycles and far fewer bugs during testing. The process means constantly exercising the ability to deploy the system from scratch, which will come in handy when an unforeseen problem occurs in the future.
Whilst this suggests a flawless venture into the Cloud sector, the journey hasn’t been without problems. CloudFormation has been incredibly useful, but given the scale and the number of resources, it has become cumbersome. Despite our best mitigation efforts there is still a large amount of repetition, and the cumulative lines of YAML we have committed is on par with the number of lines of python. We would consider using the newer AWS CDK if we were to approach the project again. Additionally, we started off making new repositories for each new Lambda, but this has ended up limiting our ability to share code effectively across components, not to mention having to update ~40 repositories when we want to update buildspecs to use a new version of python.
It has been a fascinating couple of years and a main takeaway has been that large organisations such as Met Office, with large-scale bespoke data problems, see the cloud as a desired environment for building solutions. The maturity of the AWS platform has shown the cloud to be both robust and cheap enough to satisfy the requirements of complex systems, such as SurfaceNet, and will certainly play a big part in the future of both CACI and the Met Office.