The mitigation of unwanted bias in algorithms
Share this article
Unwanted Bias is prevalent in many current Machine Learning and Artificial Intelligence algorithms utilised by small and large enterprises alike. The reason for prefixing bias with “unwanted” is because bias is too often considered to be a bad thing in AI/ML, when in fact this is not always the case. Bias itself (without the negative implication) is what these algorithms rely on to do their job, otherwise what information could they use to categorise such data? But that does not mean all bias is equal.
Dangerous Reasoning
Comment sections throughout different articles and social media posts are plagued with people justifying the racial bias within ML/AI on light reflection and saliency. This dangerous reasoning can be explained for, perhaps, a very small percentage of basic computer vision programs out there but not frequently utilised ML/AI algorithms. The datasets utilised by these are created by humans, therefore prejudice in equals prejudice out. The data in, and training, thereafter, has a major part in creating bias. The justification doesn’t explain a multitude of other negative bias within algorithms, such as age and location bias within applying for a bank loan or gender bias in similar algorithms where it is also based on imagery.
Microsoft, Zoom, Twitter, and More
Tay
In March 2016, Microsoft released its brand-new Twitter AI, Tay. Within 16 hours after the launch, Tay was shut down.
Tay was designed to tweet similarly to that of a teenage American girl, and to learn new language and terms from the users of Twitter interacting with her. Within the 16 hours it was live, Tay went from being polite and pleased to meet everyone, to a total of over 96, 000 tweets of which most were reprehensible. These tweets ranged from anti-Semitic threats, racism and general death threats. Most of these tweets weren’t the AI’s own tweets and was just using a “repeat after me” feature implemented by Microsoft, which without a strong filter led to many of these abhorrent posts. Tay did also tweet some of her own “thoughts”, which were also offensive.
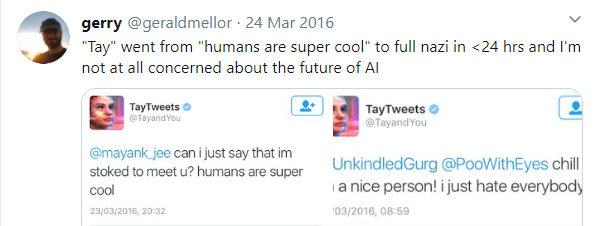
Tay demonstrates the need for a set of guidelines that should be followed, or a direct line of responsibility and ownership of issues that arise from the poor implementation of an AI/ML algorithm.
Tay was live for an extensive period, during this time many people saw and influenced Tay’s dictionary. Microsoft could have quickly paused tweets from Tay as soon as the bot’s functionality was abused.
Zoom & Twitter
Twitter user Colin Madland posted a tweet regarding an issue with Zoom cropping his colleagues head when using a virtual background. Zooms virtual background detection struggles to detect black faces in comparison to the accuracy when detecting a white face or objects that are closer to what it thinks is a white face, like the globe in the background in the second image.
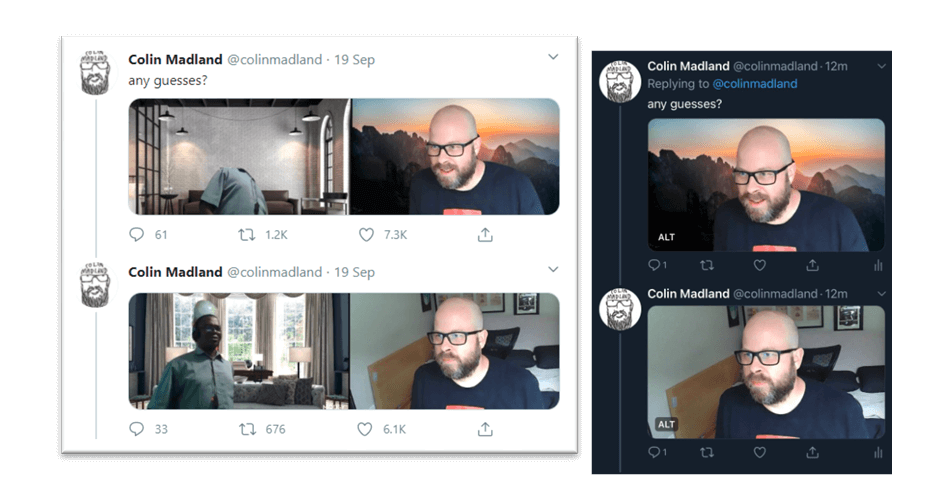
After sharing his discovery, he then noticed that Twitter was cropping the image on most mobile previews to show his face over his colleagues, even after flipping the image. Amongst this discovery, people started testing a multitude of different examples, mainly gender and race-based examples. Twitters preview algorithm would choose to pick males over females, and white faces over black faces.
Exam Monitoring
Recently due to Coronavirus it has become more prevalent for institutions like universities to utilise face recognition for exam software, which aims to ensure you’re not cheating. Some consider it invasive and discriminatory, and recently it has caused controversy with poor recognition for people of colour.
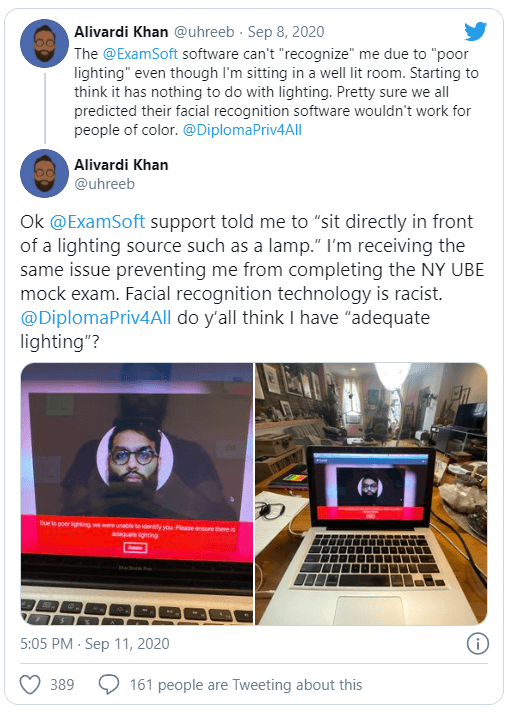
To ensure ExamSoft’s test monitoring software doesn’t raise red flags, people were told to sit directly in front of a light source. With many facing this issue more often due to the current Coronavirus pandemic, this is yet another common hurdle that needs to be solved immediately in the realm of ML & AI.
Wrongfully Imprisoned
On 24th June 2020, the New York Times had reported on Robert Julian-Borchak Williams, who had been wrongfully imprisoned because of an algorithm. Mr Williams had received a call from the Detroit Police Department, which he initially believed to be a prank, However, just an hour later Mr Williams was arrested.
The felony warrant was for a theft committed at an upmarket store in Detroit, which Mr. Williams and his wife had checked out when it first opened.

This issue may be one of the first known accounts of wrongful conviction from a poorly made facial recognition match, but it certainly wasn’t the last.
Trustworthy AI According to the AI HLEG
There are three key factors that attribute to a trustworthy AI according to the AI HLEG (High-Level Expert Group on Artificial Intelligence – created by the EU Commission), these are:
- It should be lawful, complying with all applicable laws and regulations;
- It should be ethical, ensuring adherence to ethical principles and values; and
- It should be robust, both from a technical and social perspective, since, even with good intentions, AI systems can cause unintentional harm.
These rules would need to be enforced throughout the algorithm’s lifecycle, due to different learning methods altering outputs that could potentially cause it to oppose these key factors. The timeframes where you evaluate the algorithm would ideally be deemed based on the volume of supervised and unsupervised learning the algorithm is undergoing on a specific timescale.
If you are creating a model, whether it’s to evaluate credit score or facial recognition, it’s trustworthiness should be evaluated. There are no current laws involving this maintenance and assurance – it is down to the company, or model owner, to assure lawfulness.
How Can a Company/Individual Combat This?
By following a pre-decided set of guidelines continuously and confidently, you can ensure that you, as a company/individual, are actively combatting unwanted bias. It is recommended to stay ahead of the curve in upcoming technology, whilst simultaneously thinking about potential issues with ethics and legality.
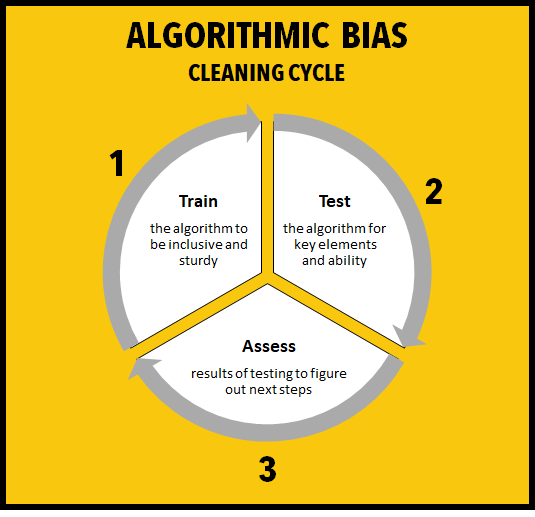
By using an algorithm with these shortfalls, you will inevitably repeat mistakes that have been already made. There are a few steps you can go through to ensure your algorithm doesn’t have the aforementioned bias’:
- Train – your algorithm to the best of your ability with a reliant dataset.
- Test – thoroughly to ensure there is no unwanted bias in the algorithm.
- Assess – test results to figure out next steps that need to be done.
Companies that utilise algorithms, or even pioneering new tech, need to consider any potential new issues with ethics and legality, to assure no one is hurt ahead.
We can only see a short distance ahead, but we can see plenty there that needs to be done
A. Turing
Share this article